
日本“最高性能AI模型”竟是DeepSeek V3改名?乐天Rakuten AI 3.0引争议








好家伙……我真的是直接好家伙!
3月17日,日本乐天(楽天)集团正式发布Rakuten AI 3.0模型,对外宣称这是“日本国内最大规模的高性能AI模型”,参数量约7000亿,主打日语特化,采用Apache 2.0开源许可,还获得了日本经济产业省和NEDO的GENIAC项目补助。

然而,这个被寄予厚望的日本国民级AI模型,发布不到12小时就爆出惊天大雷。
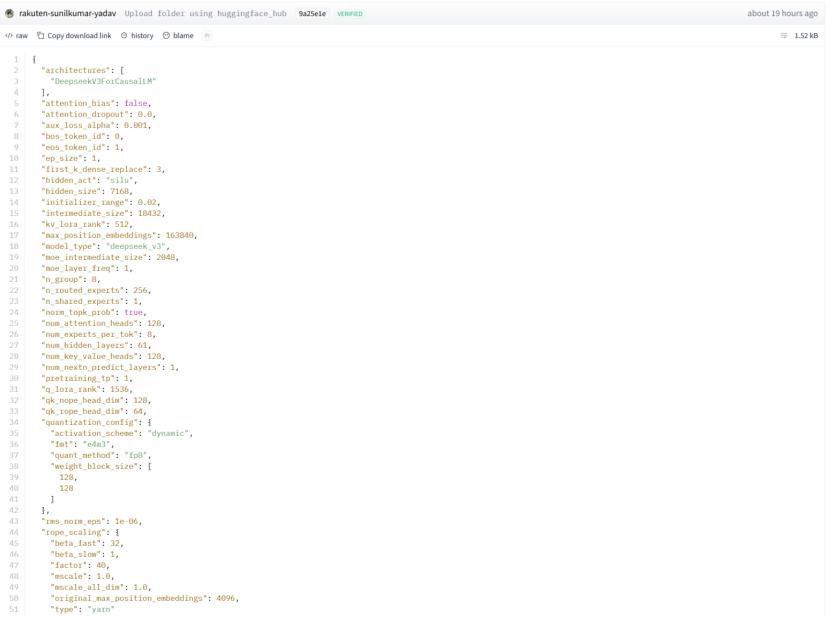
当天下午,有网友查看Rakuten AI 3.0在Hugging Face平台的config.json配置文件,第一行的architectures(架构)字段赫然显示“DeepseekV3ForCausalLM”,model_type字段也标注为“deepseek_v3”。这意味着,所谓的日本“最高性能AI模型”,本质就是中国的DeepSeek V3。

01 配置文件暴露真相,参数与DeepSeek V3完全一致
这一发现毫无技术门槛。Rakuten AI 3.0发布后,模型权重按惯例上传至Hugging Face的乐天官方仓库,任何人只需进入“Files and versions”标签页,打开config.json就能看到关键信息。
config.json是大模型的核心配置文件,记录架构细节。其中“DeepseekV3ForCausalLM”明确表示该模型采用DeepSeek V3的因果语言模型架构,并非“参考”或“借鉴”,而是直接声明模型类别。
进一步查看,hidden_size为7168、intermediate_size为18432、num_hidden_layers为61、n_routed_experts为256、vocab_size为129280——这些参数与DeepSeek V3原版配置完全一致。
更讽刺的是,DeepSeek已更新至V3.2版本,而V3本身因幻觉问题口碑不佳。乐天宣称Rakuten AI 3.0参数量约7000亿,也与DeepSeek V3的6810亿参数量高度吻合。Hugging Face页面的标签栏甚至自动生成“deepseek_v3”标签,这是系统根据config文件自动识别的结果。
乐天在官方新闻稿、Hugging Face模型卡片及PR Times通稿中均表示“基于开源社区最优秀的模型开发”,从技术层面看并未说谎——毕竟改个名字也算“开发”。DeepSeek V3是开源模型,许可证允许二次开发,乐天用日语双语数据微调优化也符合行业常规。但问题在于,乐天所有对外宣传中从未提及“DeepSeek”,这种“隐去源头”的做法引发争议。
02 网友炸锅:日本用中国AI冒充本土模型?
网友将config.json截图(高亮“DeepseekV3ForCausalLM”字段)发布到X平台后,迅速引发热议。有网友仅用“deepseek V3?”表达质疑,这条帖子被转发至日本科技媒体Impress Watch的报道推文下,评论区瞬间“翻车”。
用户Ryu评论:“日本终于到了用中国AI冒充日本产AI的时代了吗?”日语评论多为批评,中文评论则以看乐子为主。还有认证用户“ホトトギス御三家”测试模型后发现,其回答中国相关问题时符合中国价值观,而非日本本土立场,进一步加剧争议。
尽管乐天未违反开源规则,但此事颇具讽刺性:2025年DeepSeek爆火时,日本媒体曾将其比作“AI界的黑船事件”(1853年美国舰队叩开日本国门的历史事件,象征外来冲击),日本政府和企业还曾因安全疑虑限制DeepSeek使用——如今乐天却“换皮”推出基于DeepSeek V3的模型,实在令人哭笑不得。
本文来自微信公众号“字母AI”,作者:苗正,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com