
24人团队打造17000 token/秒专用芯片:通用与专用计算的未来之争





本文来自微信公众号:陆三金,作者:陆三金&kimi,原文标题:《24个人,17000 token/秒,一颗不可编程的芯片》
春节期间搜集新闻时,一个数据让人眼前一亮:有芯片能将AI推理速度提升至17000 token/秒。
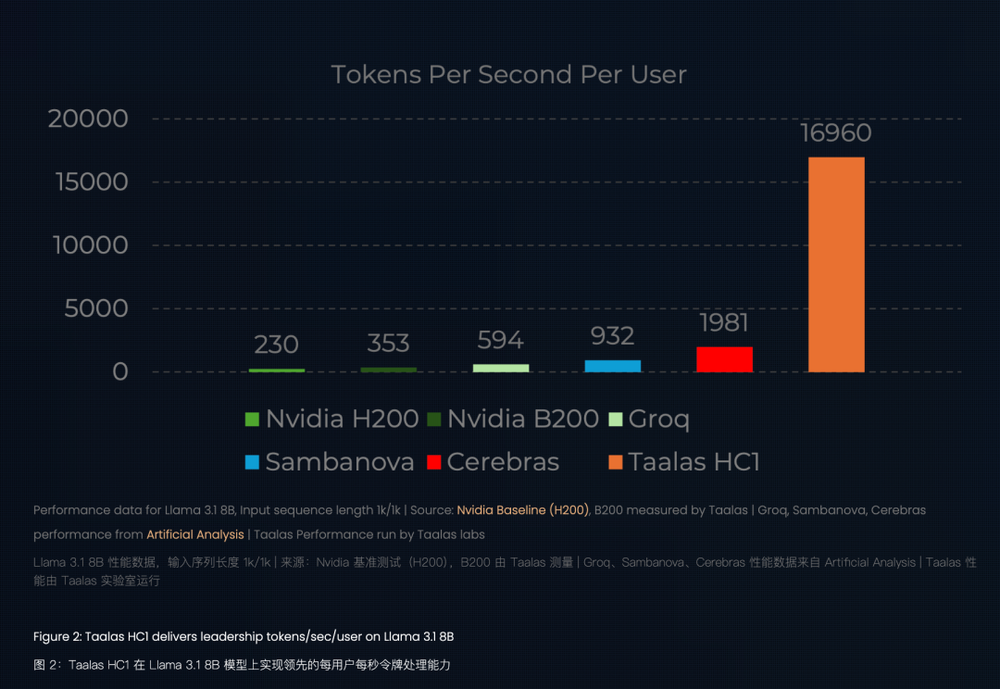
这颗芯片运行Llama 3.1 8B模型时,速度是Nvidia H200的七十多倍,功耗却仅为其零头。它无需液冷、HBM或复杂先进封装,只是一块815平方毫米的硅片,模型直接“刻”在芯片上。
值得注意的是,这颗芯片不可编程,只能运行特定模型。
研发它的公司Taalas由Ljubisa Bajic创立,他曾是Tenstorrent的CEO,带领一群共事二十年的老同事,耗时两年半打造出HC1芯片。这引发了一个经典问题:通用计算与专用计算,谁才是未来?
一
Bajic在AMD、英伟达有13年芯片设计经验,参与过ASIC和APU研发。
2016年他创立Tenstorrent,专注通用AI芯片,凭借灵活架构和软件生态崭露头角。2020年“硅仙人”Jim Keller加入后,公司知名度大增。但两年后Bajic转任CTO,Keller任CEO,不久Bajic离开。
从Taalas的路线可推测原因:Tenstorrent走通用路线,而Taalas做专用芯片。Bajic认为通用路线存在问题——现代AI推理硬件被计算与存储的速度差(上千倍)制约,厂商不得不堆HBM、搞先进封装和液冷,导致数据中心成本高、功耗大。

Taalas的解决方案是消除计算与存储的界限,将模型直接“刻”进硅片,让存储与计算合一,无需高带宽内存和复杂IO,功耗大幅降低,但代价是芯片功能单一。
二
HC1参数亮眼:台积电6纳米工艺,530亿晶体管,815平方毫米,单用户场景下17000 tokens/秒,远超Cerebras(约2000 tokens)和Nvidia H200(230 tokens),建造成本仅为二十分之一,功耗为十分之一。
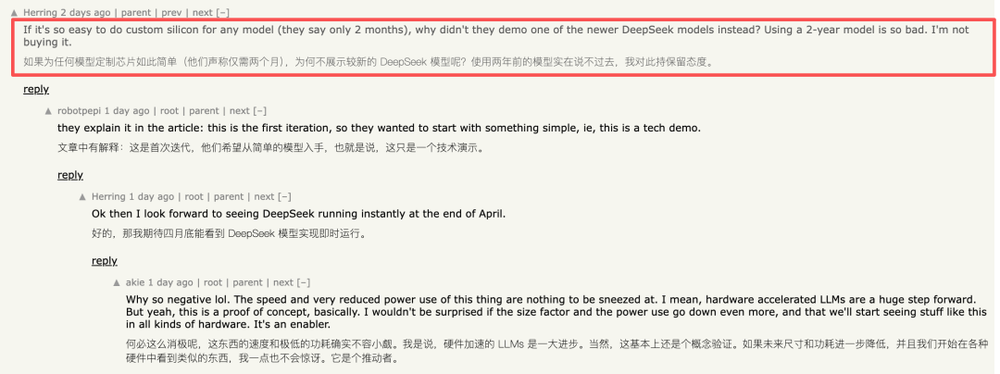
但它仅能运行Llama 3.1 8B,该模型2024年7月发布,到2026年2月已近两年。AI领域迭代迅速,期间OpenAI、Anthropic、Google等已推出多代新模型,Meta也发布了Llama 3.3,DeepSeek R1更是颠覆行业。
Taalas称“模型到硬件只需两个月”,但网友质疑:若如此,为何不展示更新的DeepSeek模型?还有人担心模型技术路线变化,如DeepSeek R1打乱众多公司计划,定制芯片可能迅速过时。Bajic也承认风险:“没人走这条路,因AI变化快,风险大。”

三
Taalas的客户需“愿意为一年承诺买单”,以摊平定制成本。但AI市场迭代快,创业公司和大厂都不敢轻易承诺。Bajic举例,DeepSeek R1 671B模型需约30颗芯片,意味着30次增量流片,虽成本低但仍繁琐。他认为总拥有成本低于GPU方案,但前提是模型架构无大变化,否则芯片可能报废。比特币挖矿ASIC的迭代历史就是教训,旧矿机迅速贬值,只有巨头能生存。Taalas面临同样问题:硬件生命周期能否追上软件变化?

四
HC1能容纳8B模型,靠的是激进量化(3-bit和6-bit混合精度),Taalas承认“相比GPU基准有质量损失”,计划第二代HC2改用4-bit浮点格式。这对高精度推理场景可能致命,且模型越大,量化损失可能越明显,硬连线方案能否适配更大模型存疑。
五
24人小团队用三千万美元造出高性能芯片,证明AI芯片领域有不同路径。技术路线选择不仅是技术问题,Taalas赌AI模型会收敛,少数架构统治市场,那时效率比灵活性重要。但当前AI市场远未收敛,DeepSeek R1的出现说明颠覆随时可能发生。将模型刻进硅片如同在流沙上盖房,地基不稳。Bajic团队用极端专用化追求极致效率,HC1是一次尝试,HC2或有新突破。这支共事超二十年的精简团队,在快速迭代的AI时代,试图让硬件追上模型速度,等待模型稳定后逆袭,充满冒险与浪漫。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com