
世界模型:自动驾驶的“仿真利器”还是终极答案?








文|肖漫
编辑|李勤
过去两三年,车企谈及智能驾驶时,总会抛出各类新颖技术名词。
世界模型是继端到端、VLA之后,智驾领域最热门的概念。不同企业还给它赋予了独特名称——小鹏推出“世界基座模型”、蔚来提出“端到端世界模型”、华为打造“世界行为模型”(WA)。此外,地平线、理想、元戎启行、Momenta等企业也在布局世界模型相关技术。
但仅看企业发布会,很难分辨这些“世界模型”是否为同一技术;它究竟解决什么问题,又在智能驾驶架构中处于什么位置?
从广义语境来看,“世界模型”本质是在虚拟空间重建真实世界,让人工智能能像人类一样理解现实,认知物理规律、事物因果关系及环境动态变化的技术。
世界模型被多数科学家和科技公司视为“物理世界AI”发展的关键。斯坦福大学教授李飞飞曾表示,空间智能是AI的下一个十年,而世界模型是构建空间智能的核心技术。
前沿科学家和企业仍在探索,但中国汽车行业已用各类新颖概念占据了赛道位置。
实际上,当前智驾行业的“世界模型”只是名词表述不同,技术路径差异不大。它是对原有仿真工具的技术范式升级,通过还原度、颗粒度更高,场景更丰富、自由度更强的虚拟世界,解决端到端模型的测试与验证问题,最终目标是训练出更高效、更拟人化的端到端智驾模型。
简单来说,智驾厂商和车企并非打造完整的数字物理世界,只是用世界模型的思路构建仿真器。
尽管各家对世界模型的期待不同,但据了解,目前智驾行业的世界模型仅应用于云端,尚未实现在汽车端的部署。
端到端普及,暴露传统仿真器不足
过去两三年,头部智驾方案从规则栈转向AI驱动,在形式上实现统一:将感知、预测、规划尽可能整合到一个网络中,搭配更大模型和更高算力。正如车企发布会上常说的,“端到端后的智驾更像人开车”。
但实际应用中出现了反直觉现象:端到端后的新版本OTA不一定更优,甚至可能“退步”。
问题核心并非模型变差,而是AI驱动让评估与回归更困难。
此前许多智驾从业者认为,只要前端训练足够好,车辆就能像人一样驾驶。这条路径初期效果显著,让从业者震撼,但端到端的“黑盒”特性也带来副作用:模型出错时,研发人员难以知晓原因,也无法证明下次不会再犯。
模型优劣不再仅取决于“训练规模和数据量”,更在于能否发现、定义和验证问题。厂商逐渐意识到,需要更优的仿真器在模型验证阶段评估其表现。
头部企业大多将世界模型作为仿真器应用。为让理想VLA在仿真环境中进行强化学习,理想在2025年提出包含自车和他车轨迹的驾驶世界模型,充当“打分老师”;小鹏虽对外提及“世界基座模型”这一与世界模型本质无关的名词,但据36氪汽车了解,其也在利用世界模型进行仿真测试,评测新版本模型算法能力。
端到端的普及凸显了传统仿真器的短板。“以前端到端未普及,验证成本不高,还能分段验证系统。但端到端后无法分段验证,仿真器的问题就暴露了。”一位业内研发人员表示。
在规则时代,车企做仿真主要服务两件事:一是重现半路接管的问题,回放路测中出现问题的片段;二是通过仿真器增加corner case的数据丰富度,在模拟器中搭建典型路口、横穿行人、加塞车辆等脚本场景,让系统运行测试。
当时的仿真器更像“放大镜”,但端到端后,模型责任难以拆分,也难以系统性生成更细致、可控的corner case,更无法支撑端到端所需的大规模闭环验证——这正是引入世界模型的原因。
端到端时代,世界模型是智驾模型的“教练”
“目前国内车企世界模型的水平与特斯拉存在一定差距,但相差不到一年时间。”一位业内人士称。
特斯拉未使用“世界模型”概念,而是提出“世界模拟器”(去年ICCV上由特斯拉自动驾驶副总裁Ashok Elluswamy首次提及)。该模拟器基于特斯拉自建的海量数据集训练,能根据当前状态和下一步动作生成未来状态,与车端端到端基础模型形成闭环,进行真实效果评估。
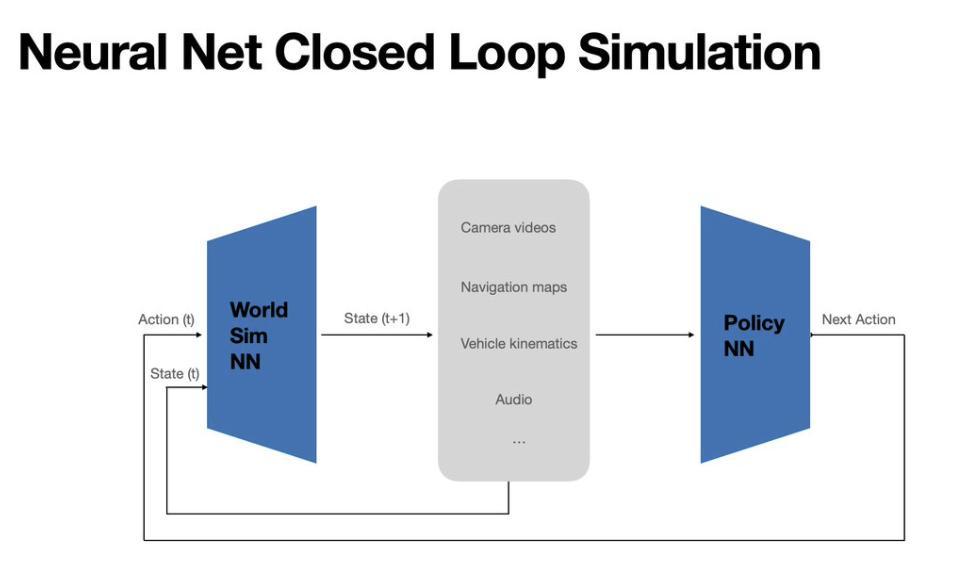
一位业内人士指出,特斯拉更倾向用神经网络“拟合”世界,渲染过程通过计算生成,尽量减少显式物理规则堆叠;素材库并非完全由人预定义,而是保留了概率权重与组合空间,这样能增强模型的泛化能力。
国内车企多选择更“可控”的路线。与36氪汽车交流的一家供应商表示,理想采用3D高斯重建——这也是目前多数车企采用的方式之一。
无论哪种路线,世界模型在工程上最终指向同一方向:车企将其作为端到端时代的“验证与反证系统”,在云端重放、改写、扩增现实驾驶中可能出现的情境,检验车端大模型输出是否稳定、可复现,并让“哪里错、为什么错”重新成为可追踪的证据链。
世界模型的角色类似教练员,优秀的教练能培养出优秀的运动员。“随着云端世界模型不断增强,理论上车端模型的能力也会越来越强。”一位研发人员说。
世界模型的核心能力主要有两方面:一是对物理世界的数字化建模与抽象;二是基于建模,对物理世界进行合理想象和预测,比如通过给定图片预测未来世界的变化。
世界模型的好坏取决于能否在云端生成足够真实、多样的数据。“如果车企只是用采集的真实数据做仿真,那不是在做世界模型,只是一套回放数据的流程。”一位供应商产品经理表示。
世界模型需要从物理世界数据中学习运行模式,因此训练数据质量会显著影响生成质量。极佳视界产品线负责人毛继明提到:“对于世界模型这类生成模型,生成结果最终会对齐输入数据的特征分布规律。在真实商业化过程中发现,如果数据质量只有60分,基于此的世界模型生成数据质量可能只有55分。”
借助世界模型,车企在云端做仿真时,可从各维度无限生成所需场景,还能根据指令生成视频作为训练数据。“效率比真实采集后再训练高很多,模型迭代速度会实现断代式领先。”一位供应商研发人员称。
但这些都是理想化结果。“世界模型相比智驾用的仿真器,或不用仿真信息仅用离线数据验证,已是很大升级,但距离理想仿真器还有差距。”
世界模型算法尚未成熟,仍存“幻觉”问题
行业目前普遍处于起步阶段。
一位车企研发人员告诉36氪汽车,国内厂商基于世界模型最长能生成30-60秒的视频片段,但动态物体的一致性不佳,时空一致性和多视角一致性都存在较大问题。
世界模型底层是生成式模型,天生存在“幻觉”风险。“目前世界模型最难的是保证生成内容的真实性,比如生成的人,其行为、轨迹要符合真实世界逻辑。”一位供应商产品经理表示,“如果世界模型生成错乱,会导致模型学到错误信息,进而让车端模型效果变差。”
一个极端例子:如果云端生成的车都是横着走的,模型会认为左前方的车会瞬间移动到右前方,实际驾驶中可能做出刹车动作。
若仿真器无法逼近现实世界的关键因果关系,比如湿滑路面对制动距离的影响、逆光下静止物体的误检概率、并线时对方车辆的博弈策略等,生成的“corner case”可能是虚假的;在假问题上优化,等于浪费研发资源在幻影上。
很多人认为世界模型的瓶颈在数据与算力,但前理想汽车辅助驾驶“端到端”模型负责人夏中谱更认同Lecun的观点:“世界模型算法层面没有大突破,图像模型的自监督训练还未找到像语言模型那样顺畅的范式。”
语言模型能快速规模化,原因之一是语言信息密度高,每个词都有明确语义约束。而图像信息密度低,对“驾驶决策”而言,有用信息占比极小。
例如,模型无需预测正后方远处车辆的轨迹,也无需预测远处建筑物的变化,这些都是噪声数据;但必须预测本车道前车是否会急刹、旁车是否会抢道、行人是否会横穿,模型要先知道“该关注什么”。
“目前智驾算法无法提取足够对驾驶有用的图像信息。”夏中谱说。一张图像可能有上百万像素点,但与决策相关的仅20多个,其他都是噪声,模型需先学会从噪声中抓取1‰甚至1‱的有效信号,再将信号组织成可用于推理和预测的结构。
在夏中谱看来,世界模型算法尚未突破,更谈不上数据是否足够、算力是否充足的问题。正因基础技术无明确突破,车企投入多为研究性质,部分车企老板对此也很迷茫。
若世界模型足够好且算力支撑,是可以部署到车端的。“国内现在基本把世界模型当仿真系统用,对智驾决策层面的技术理解还不够。”夏中谱表示。
这也解释了一个表面矛盾:为何各家都在讲世界模型,但用户体感差异不明显——因为多数企业的世界模型仍停留在“训练与验证”的第一阶段,尚未进入“支撑决策规划”的第二阶段。
“在车端部署世界模型是最难的。”夏中谱说。
目前尚无企业在车端应用世界模型。他同时指出:“用大模型方法建模物理世界,通过与物理世界交互预测发展变化,进而通过决策让世界朝有利方向发展。若世界模型能做到这一步,自动驾驶和机器人相关问题都能解决。”
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com