
估值840亿AI实验室新成果:给大模型训练加「紧箍咒」





近日,由OpenAI前CTO Mira Murati创办的Thinking Machines Lab再次发布研究成果。这是他们继《克服LLM推理中的不确定性》之后的第二篇研究文章——《模块流形》。
博客地址:https://thinkingmachines.ai/blog/modular-manifolds/
训练大型神经网络如同在钢丝上行走,需要小心维持其内部「健康」,防止权重、激活值或梯度等关键张量过大或过小,避免引发数值溢出等问题。其中一个重要思路是为大模型提供统一的量级管理。
首先要稳住基本盘。常用的做法是使用Layer Norm技术,将每层的输出拉回合适范围,对激活向量进行归一化。对梯度更新进行归一化也很常见,例如Muon优化器对更新进行谱归一化处理,使每一步更新的幅度可控。
更进一步,是直接「管住」权重本体。归一化权重矩阵是一个可行方向。文中提出了新视角:将权重张量约束在某个子流形上,与这些流形约束协同设计优化算法。这就好比把「救火」变为「预防」,一开始就将参数置于健康区间,让训练更稳定、更具解释性,使大模型能更高效地训练。
流形优化器的形态
流形是一个局部看起来很平坦的曲面,放大到足够程度,它就像普通平面。流形上某一点附近的局部平坦空间称为「切空间」。

如图1所示,三维球面或更高维度的超球面是流形,图中红色部分表示其在某点的切平面。为了让权重待在指定流形里,简单方法是使用普通优化器,每步更新后将权重投影回流形。但如果优化步骤偏离流形太多,再强制投影回来,会导致名义学习率与参数在流形上的实际位移不对应,削弱我们对「步长—效果」关系的直觉。
要在流形上设计训练算法,需先明确在切空间里如何度量「距离」。一个解决思路是直接在切空间中进行优化,让每一步沿着流形「表面」走,使学习率更好地对应「实际位移」。常见选择是欧几里得距离,也可采用其他方式测量距离,如图2所示。
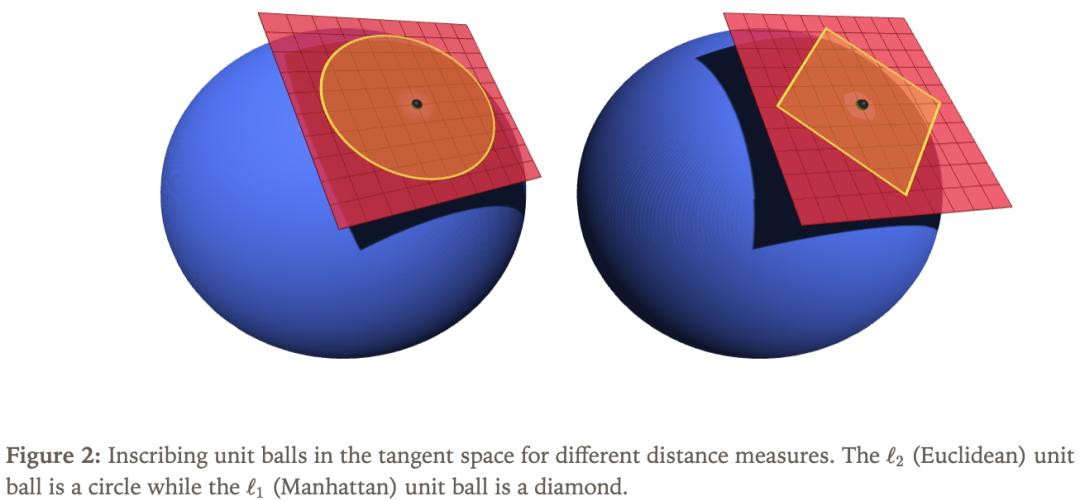
值得注意的是,距离度量方式的选择会直接影响最优优化步骤的方向。
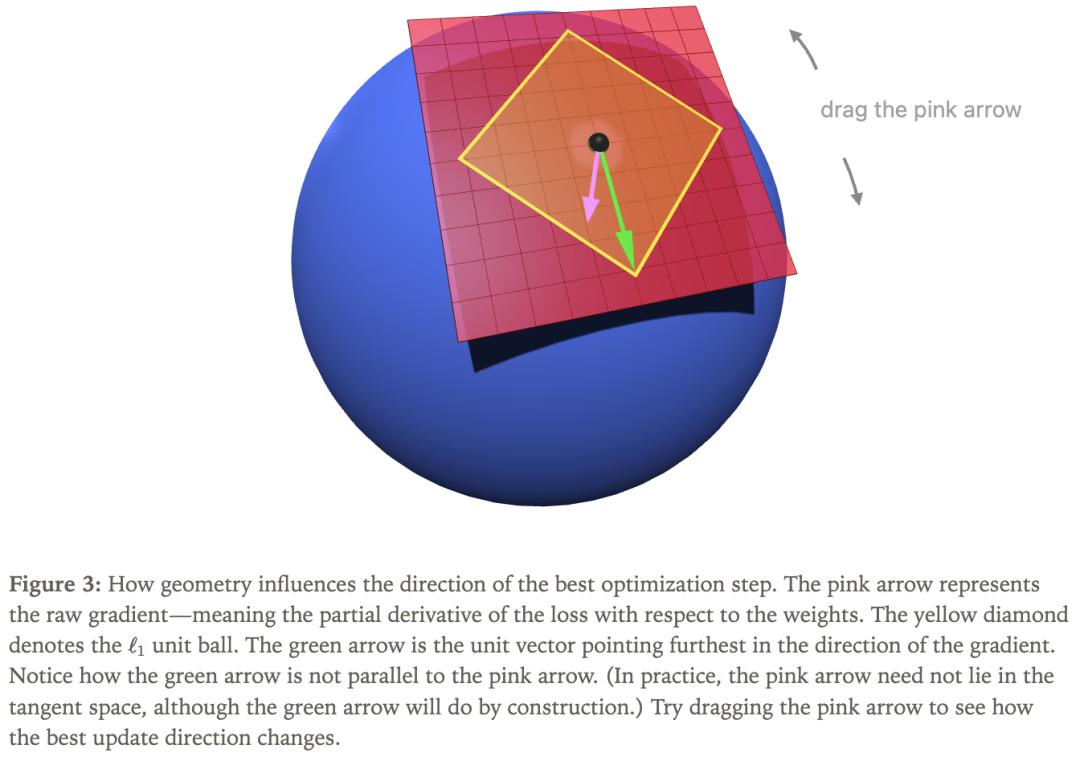
图3中,粉色箭头表示原始梯度,即损失函数对权重的偏导数。这意味着我们不一定严格按照梯度方向移动。为了用数学表达这个过程,可将「在流形约束和特定距离度量下的最优更新方向」看作带约束的优化问题,以搭配欧几里得范数的超球面为例。
用g表示梯度, w表示超球面上的当前点, a表示更新方向, η表示学习率,我们需要解决的问题是:
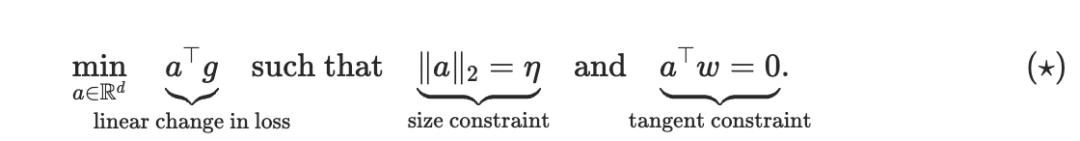
结合图 1、2 和3,这个公式的意思是:绿色箭头(即a的最优解)必须同时满足两个条件:一是落在红色的切平面上,二是在半径为η的黄色圆圈上。
我们可以用拉格朗日乘数法求解。
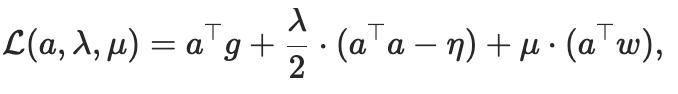
其中λ和μ是拉格朗日乘子。对拉格朗日函数对a求导并令其为零,结合两个约束条件求解λ和μ,可得到最优更新方向。
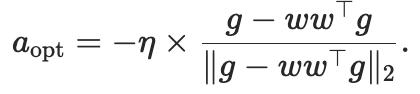
简单来说,最优更新做法是:先从梯度中减去与w同方向的径向分量,将梯度投影到切空间上,然后将结果归一化,再乘以学习率。这样得到的更新方向就在切空间里。
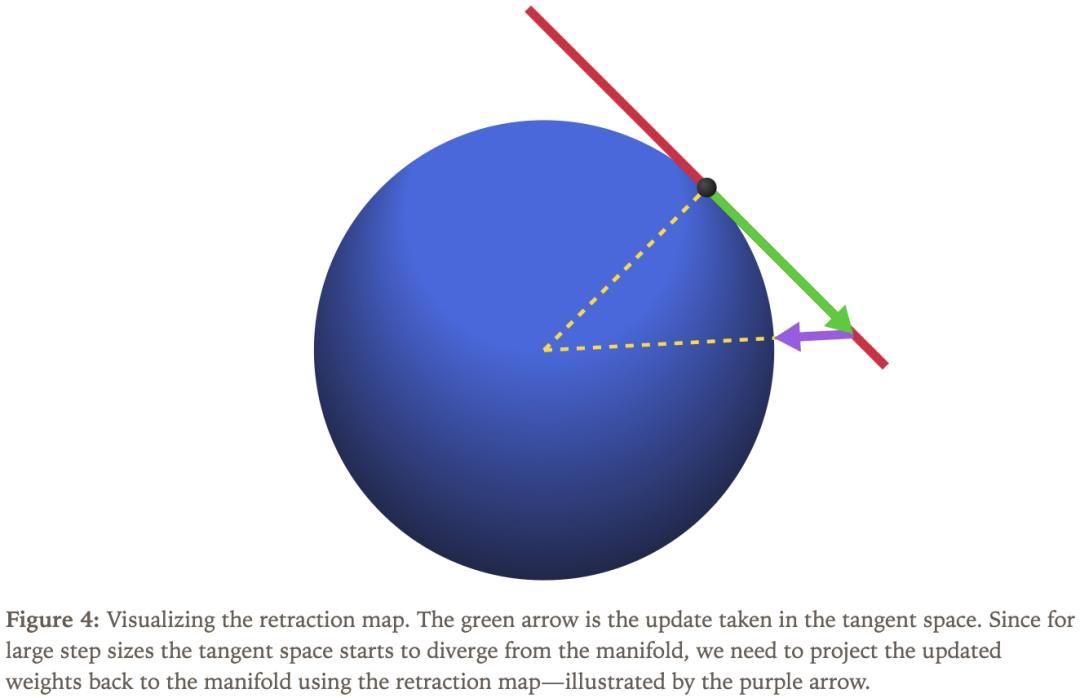
图4中,这个微小的修正过程被称为「回缩映射」。完整的流形优化算法如下:
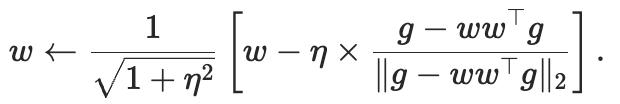
总结来说,一阶流形优化器包含三个步骤:找到一个单位长度的切向量,在梯度方向上尽可能远;用学习率乘以这个方向,然后从当前权重中减去;把更新后的权重通过回缩映射拉回流形上。
执行这一流程时,需要决定选择什么样的流形作为约束,以及如何定义「长度」的度量方式。根据这两个选择的不同,可得到不同的优化算法,具体见下表。
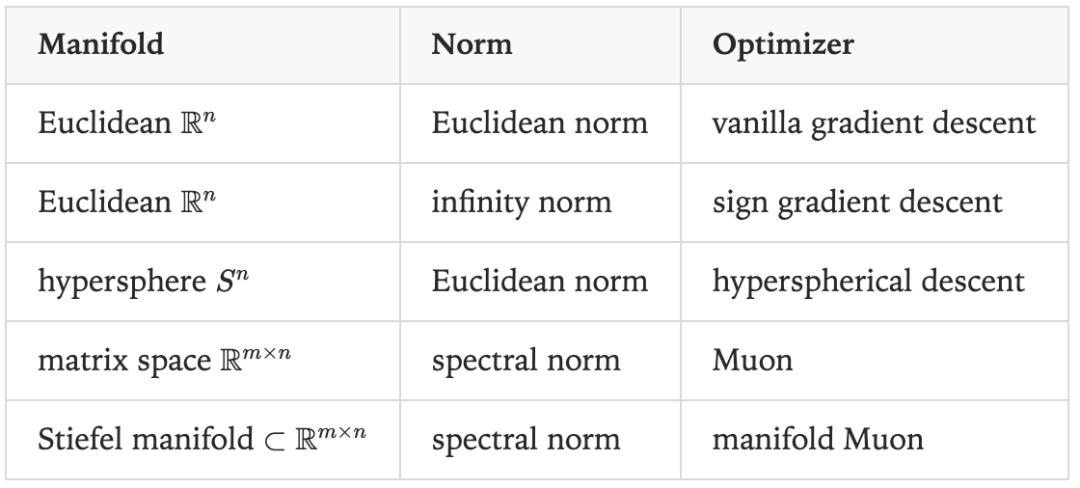
流形Muon
Transformer中的典型权重矩阵W是「向量变换器」,将输入向量x转换为输出向量y=Wx。我们希望设计一种流形约束和距离函数,使该矩阵对输入向量的作用合理,避免输出值过大或过小,以及更新权重时输出向量剧烈变化或几乎无变化。
使用奇异值分解(SVD)是思考矩阵如何作用于向量的好方法,如图 5 所示。SVD以分解矩阵的方式显示矩阵如何沿着不同的轴拉伸输入向量。
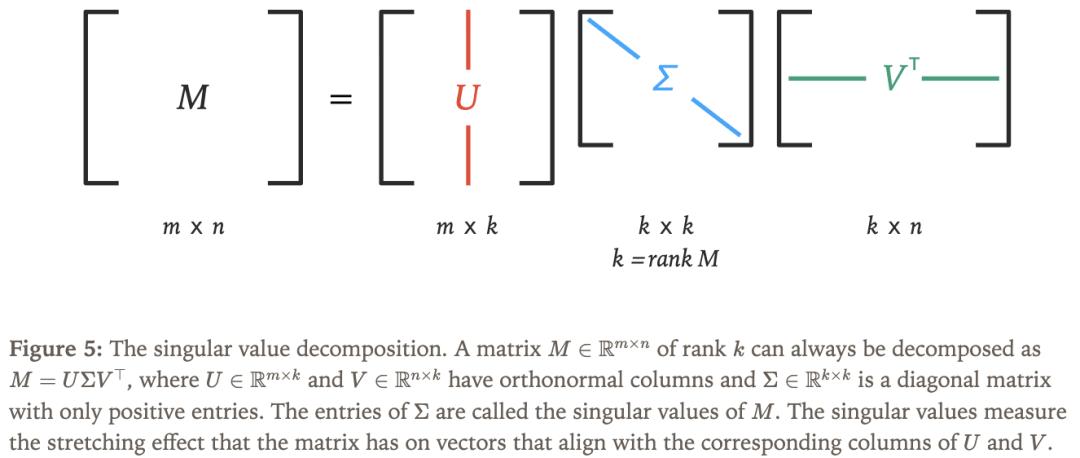
我们希望矩阵的「拉伸效应」接近于1,因此选择所有奇异值均为1的矩阵流形。这种矩阵流形在数学上被称为Stiefel流形,在高矩阵( m≥n)的假设下,它可以等价地定义为以下集合:
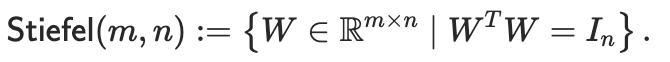
要为Stiefel流形设计优化器,还需选择合适的距离函数。为限制权重更新对输入向量的最大拉伸作用,谱范数是合适的选项。虽然它只约束了最大效应,但由于优化器会饱和这一上限,也能间接防止最小效应过小。这一想法促成了Muon优化器的提出。
这一想法与Stiefel流形约束结合后,形成了「manifold Muon」问题。

文中的一个关键发现是一个凸优化问题,可通过标准方法——对偶上升法来求解。

经过推导,对偶函数的梯度为:
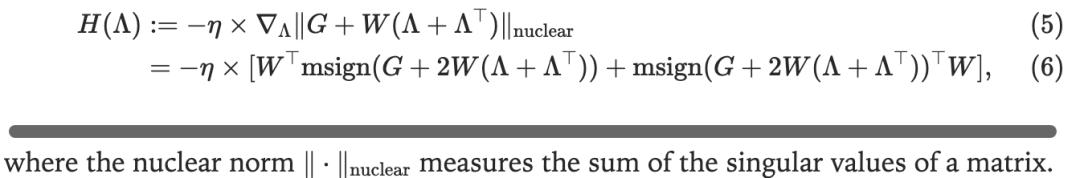
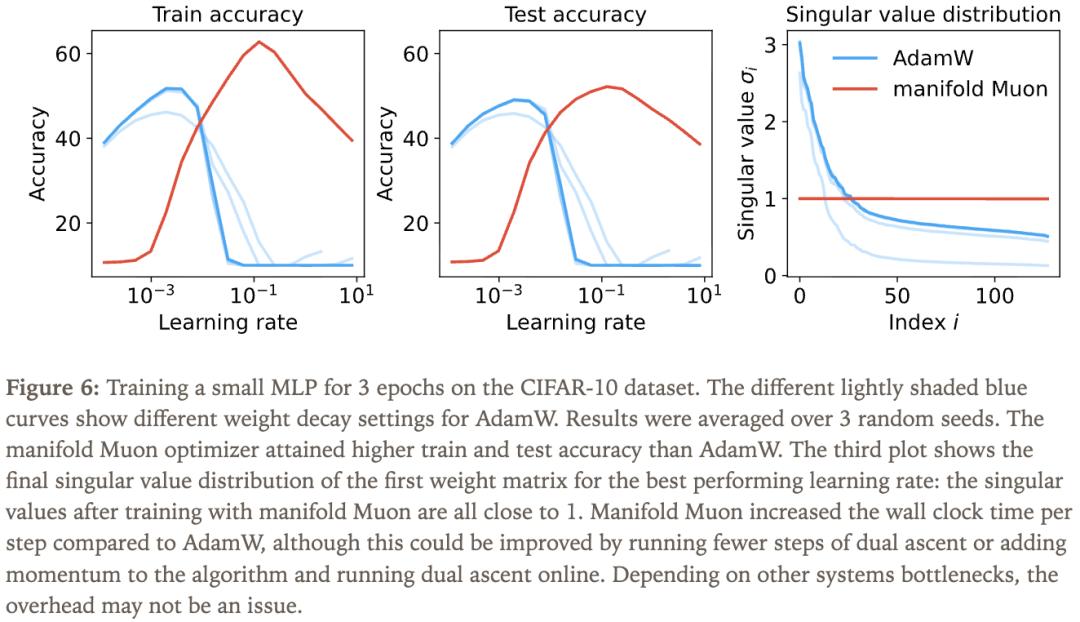
通过一个小实验,可以验证算法的可行性,实验设置与结果见图6。
模块流形
当我们将多个层组合起来构建完整的神经网络时,会出现什么情况?是否需要关注层与层之间的交互,并据此修改优化策略?这就需要模块流形理论,它可以将前文的推导逻辑推广到整个神经网络。
该理论的核心思想是构建一种抽象机制,指导如何在各层之间合理分配学习率。本质上,在不同层之间分配学习率,或对单个层进行缩放,都依赖于我们对网络输出对权重的Lipschitz敏感性的理解。我们在搭建网络的过程中会追踪这种敏感性,而流形约束有助于我们更精准地把握它。
参考资料:
https://thinkingmachines.ai/blog/modular-manifolds/
本文来自微信公众号“新智元”,作者:新智元,编辑:元宇,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com