
谷歌揭秘Genie 3:Sora后最强AI爆款,开启世界模型新纪元
2025-08-18






Genie 3是迈向AGI的重要一步,它是有史以来最先进的世界模型之一。仅依靠文本,它就能实时生成完全互动、高度一致的世界。它不仅是DeepMind多年积累的成果,更是通向AGI和具身智能体的关键一环。那么,Genie 3是如何构建的?未来的世界模型又会是什么模样呢?
刚刚,谷歌DeepMind的研究科学家Jack Parker - Holder和研究总监Shlomi Fruchter,在a16z的访谈中分享了他们的见解。

这次对话让我们得以第一手了解Genie 3。主持人Justine Moore发推称:「Genie 3在网络上引发热潮」。

他总结了访谈要点:
Genie 3是由两个DeepMind项目(Veo 2和Genie 2)合作的结晶。
实时、互动的世界模型有诸多潜在应用。
不过,应用并非推动研究的主要动力,它们是在用户使用模型的过程中自然产生的。
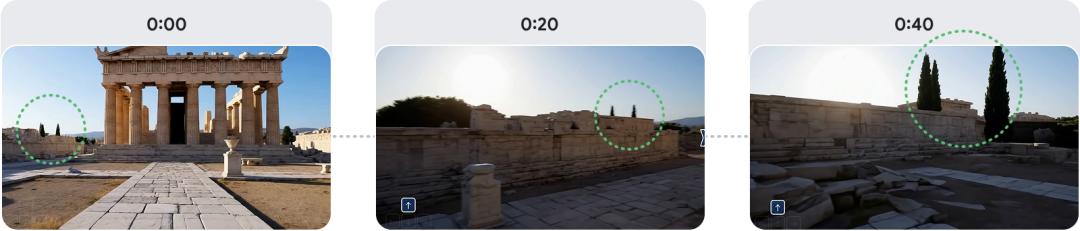
Genie 3可保留长达一分钟的空间记忆。
物理规律是模型的「自然产物」,会随训练数据的规模和深度不断提升。
目前还没有一个「终极模型」能同时具备Veo 3和Genie 3的所有能力。
十多年来,谷歌DeepMind一直专注于模拟环境的研究。Genie 3是他们最新、最强的「世界模型」,是通向通用人工智能(AGI)的关键一步,因为它能让AI智能体在无限丰富的模拟环境中训练。
去年,他们推出了首批基础世界模型Genie 1和Genie 2,能为智能体生成全新环境。此外,他们还通过Veo 2和Veo 3等视频生成模型,不断提升对直观物理的理解能力。
这些模型在世界模拟的不同能力上都有进步。Genie 3是谷歌首个支持实时交互的世界模型,同时提升了一致性和真实感。
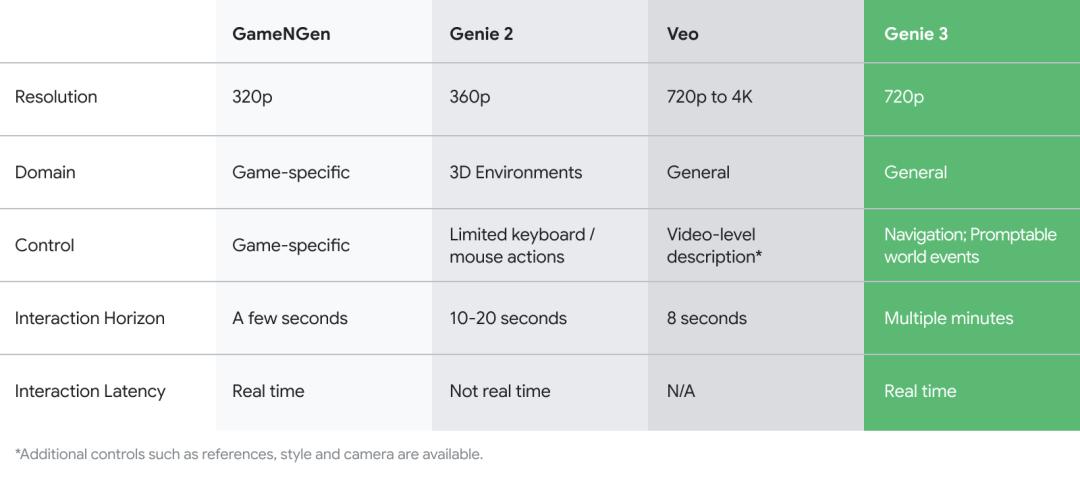
Genie 3在生成视频时长、世界一致性、内容多样性、特殊记忆等方面都实现了突破。它甚至能让个人创造自己的游戏世界、训练强化学习的智能体、用于机器人研究等。所有这些应用都源于一个核心能力:只用几句话就能生成一个完整的世界。
最关键的新特性是:特殊记忆。
比如,一个角色拿着刷子在墙上刷漆,然后移动到墙的另一边刷,再回到原来位置,之前刷的痕迹依然存在。特殊记忆是DeepMind团队有意设计的目标,最终效果好得超出预期。就连Genie 3的内部成员,第一次看到刷墙示例时都不敢相信,要再三观看、逐帧检查才确定是模型生成的。
其实,Genie 2就有一些「记忆能力」,但当时AI界有很多令人激动的模型发布,谷歌主打的卖点是「可以生成新的世界」,所以记忆能力未被重点强调。到了Genie 3,谷歌DeepMind明确把「增强记忆能力」作为核心目标之一。
当时设定的目标是:
超过一分钟的记忆、
支持「实时生成」、
还能提升「分辨率」。
这几个目标相互矛盾,但谷歌毫不畏惧。直到项目快结束,看到最终样本时,他们仍感到震撼。毕竟,研究项目没有百分百的确定性。
在设计上,他们明确不采用「显式表示法」。市面上有些方法,如用NeRF或Gaussian Splatting等技术构建明确的3D世界结构来达到一致性,效果不错。但他们坚持让模型「逐帧生成」,这种方式更有助于模型的泛化能力和适应多样世界的能力。
而且,模型对语言的理解不断提升,生成内容更真实,视觉效果更自然。从Genie 2到Genie 3的提升很明显,特别是在「模拟现实世界能力」上有巨大飞跃。
比如物理效果的表现,像水的模拟、光照的变化都很惊艳,现在非专业人士看了也会觉得是真实拍摄的视频。而在Genie 2时代,一眼就能看出是AI生成的。
现在的视频真假难辨,进步显著。
在「地形多样性」方面,模型需要理解在沙地上行走、下坡滑雪、水中游泳等不同动作和物理反馈。谷歌团队发现这些行为大多是规模和数据广度带来的「涌现能力」,即模型通过丰富的训练数据掌握了「世界」的通用常识,多数时候表现良好。
比如,滑雪时角色下坡速度变快,上坡变慢甚至爬不上去;下水后角色会游泳或溅起水花;靠近水坑时,模型会让角色穿上雨靴。这些行为自然,与人类对真实世界的理解一致,就像魔法一样。
这里还有一个有趣的权衡:既能保持世界的「物理一致性」,又能忠实地执行用户的提示词。对视频模型来说,「低概率事件」很难,但Genie 3表现不错。即便现实中不太可能发生的场景,Genie 3也能让人身临其境,而不是生成无聊的视频。
在「指令跟随/文本对齐」方面,Genie 3也有提升,这得益于DeepMind内部不同项目(特别是Veo项目)的经验迁移和知识共享,跨团队协作是DeepMind的优势。世界模型是让智能体走向现实世界的捷径,Genie 3朝着这个目标迈进了一大步。那么,Genie 4、Genie 5会有哪些新特性呢?
诚然,世界模型距离「准确模拟现实世界」还有很大差距。比如,把人放进生成的世界里随心所欲做事,目前还做不到。要让虚拟世界的真实感和自由度接近现实,还有很多工作要做。
应用有很多,关键在于能否准确模拟世界,并把人放进去。也许还能从「第三视角」观察自己,或与虚拟智能体互动。
他们还透露真实感和交互性是未来的关键。目前机器人领域最大的瓶颈之一是数据有限,而Genie 3能生成几乎无限的场景,机器人可以在虚拟世界里学习,不再局限于现实采集的视频,这一想法令人兴奋。
最后一个问题:人类是否生活在某种模拟中?这个问题被多次提及,得到了「哲学化」的回答:如果是模拟,那它运行在完全不同的硬件之上。如果人类真生活在模拟世界,那绝不是运行在现在的硬件上,因为我们的世界是连续的,不是数字化的,所有感知都是连续信号。也许在量子层面有「硬件限制」,但和现在的计算机完全不同。或许未来量子计算机才是运行我们这个模拟世界的真正平台。
本文来自微信公众号“新智元”,作者:新智元,36氪经授权发布。
刚刚,谷歌DeepMind的研究科学家Jack Parker - Holder和研究总监Shlomi Fruchter,在a16z的访谈中分享了他们的见解。
这次对话让我们得以第一手了解Genie 3。主持人Justine Moore发推称:「Genie 3在网络上引发热潮」。
他总结了访谈要点:
Genie 3是由两个DeepMind项目(Veo 2和Genie 2)合作的结晶。
实时、互动的世界模型有诸多潜在应用。
不过,应用并非推动研究的主要动力,它们是在用户使用模型的过程中自然产生的。
Genie 3可保留长达一分钟的空间记忆。
物理规律是模型的「自然产物」,会随训练数据的规模和深度不断提升。
目前还没有一个「终极模型」能同时具备Veo 3和Genie 3的所有能力。
Genie 3:AI新魔法
如果说LLM的原生图像编辑功能「动动嘴PS」是「言出法随」,那Genie 3这次的新特性该怎么形容呢?只需输入文本提示,Genie 3就能生成动态世界,用户可以实时探索,每秒可达24帧,分辨率为720p。十多年来,谷歌DeepMind一直专注于模拟环境的研究。Genie 3是他们最新、最强的「世界模型」,是通向通用人工智能(AGI)的关键一步,因为它能让AI智能体在无限丰富的模拟环境中训练。
去年,他们推出了首批基础世界模型Genie 1和Genie 2,能为智能体生成全新环境。此外,他们还通过Veo 2和Veo 3等视频生成模型,不断提升对直观物理的理解能力。
这些模型在世界模拟的不同能力上都有进步。Genie 3是谷歌首个支持实时交互的世界模型,同时提升了一致性和真实感。
Genie 3在生成视频时长、世界一致性、内容多样性、特殊记忆等方面都实现了突破。它甚至能让个人创造自己的游戏世界、训练强化学习的智能体、用于机器人研究等。所有这些应用都源于一个核心能力:只用几句话就能生成一个完整的世界。
最关键的新特性是:特殊记忆。
比如,一个角色拿着刷子在墙上刷漆,然后移动到墙的另一边刷,再回到原来位置,之前刷的痕迹依然存在。特殊记忆是DeepMind团队有意设计的目标,最终效果好得超出预期。就连Genie 3的内部成员,第一次看到刷墙示例时都不敢相信,要再三观看、逐帧检查才确定是模型生成的。
其实,Genie 2就有一些「记忆能力」,但当时AI界有很多令人激动的模型发布,谷歌主打的卖点是「可以生成新的世界」,所以记忆能力未被重点强调。到了Genie 3,谷歌DeepMind明确把「增强记忆能力」作为核心目标之一。
当时设定的目标是:
超过一分钟的记忆、
支持「实时生成」、
还能提升「分辨率」。
这几个目标相互矛盾,但谷歌毫不畏惧。直到项目快结束,看到最终样本时,他们仍感到震撼。毕竟,研究项目没有百分百的确定性。
在设计上,他们明确不采用「显式表示法」。市面上有些方法,如用NeRF或Gaussian Splatting等技术构建明确的3D世界结构来达到一致性,效果不错。但他们坚持让模型「逐帧生成」,这种方式更有助于模型的泛化能力和适应多样世界的能力。
智能涌现,惊喜不断
和其他生成式模型一样,随着规模扩大,效果会提升,这已不是秘密。尽管Genie 3在推理能力的涌现表现不如语言模型,但它依然涌现出一些令人惊喜的行为。比如,一个角色靠近门时,模型可能会「推测」角色应打开门;这类符合人类直觉的行为,模型现在能一定程度上表现出来。而且,模型对语言的理解不断提升,生成内容更真实,视觉效果更自然。从Genie 2到Genie 3的提升很明显,特别是在「模拟现实世界能力」上有巨大飞跃。
比如物理效果的表现,像水的模拟、光照的变化都很惊艳,现在非专业人士看了也会觉得是真实拍摄的视频。而在Genie 2时代,一眼就能看出是AI生成的。
现在的视频真假难辨,进步显著。
在「地形多样性」方面,模型需要理解在沙地上行走、下坡滑雪、水中游泳等不同动作和物理反馈。谷歌团队发现这些行为大多是规模和数据广度带来的「涌现能力」,即模型通过丰富的训练数据掌握了「世界」的通用常识,多数时候表现良好。
比如,滑雪时角色下坡速度变快,上坡变慢甚至爬不上去;下水后角色会游泳或溅起水花;靠近水坑时,模型会让角色穿上雨靴。这些行为自然,与人类对真实世界的理解一致,就像魔法一样。
这里还有一个有趣的权衡:既能保持世界的「物理一致性」,又能忠实地执行用户的提示词。对视频模型来说,「低概率事件」很难,但Genie 3表现不错。即便现实中不太可能发生的场景,Genie 3也能让人身临其境,而不是生成无聊的视频。
在「指令跟随/文本对齐」方面,Genie 3也有提升,这得益于DeepMind内部不同项目(特别是Veo项目)的经验迁移和知识共享,跨团队协作是DeepMind的优势。世界模型是让智能体走向现实世界的捷径,Genie 3朝着这个目标迈进了一大步。那么,Genie 4、Genie 5会有哪些新特性呢?
未来的关键,真实感和交互性
总体而言,Genie 3团队最关注的是让模型更强大,产生更广泛影响,然后把创造应用的机会交给其他团队。他们表示最终会开放Genie 3模型。诚然,世界模型距离「准确模拟现实世界」还有很大差距。比如,把人放进生成的世界里随心所欲做事,目前还做不到。要让虚拟世界的真实感和自由度接近现实,还有很多工作要做。
应用有很多,关键在于能否准确模拟世界,并把人放进去。也许还能从「第三视角」观察自己,或与虚拟智能体互动。
他们还透露真实感和交互性是未来的关键。目前机器人领域最大的瓶颈之一是数据有限,而Genie 3能生成几乎无限的场景,机器人可以在虚拟世界里学习,不再局限于现实采集的视频,这一想法令人兴奋。
最后一个问题:人类是否生活在某种模拟中?这个问题被多次提及,得到了「哲学化」的回答:如果是模拟,那它运行在完全不同的硬件之上。如果人类真生活在模拟世界,那绝不是运行在现在的硬件上,因为我们的世界是连续的,不是数字化的,所有感知都是连续信号。也许在量子层面有「硬件限制」,但和现在的计算机完全不同。或许未来量子计算机才是运行我们这个模拟世界的真正平台。
本文来自微信公众号“新智元”,作者:新智元,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com