
LeCun亲自出现打脸质疑者,憋了20年AI世界模型,终于爆发了。









刚才,LeCun居然亲自出现,重磅介绍了V-JEPA 2!就在外界猜测他已经被边缘化的时候,AI老将用一个视频回应质疑:做一个世界模型要不动摇!这个孤独勇敢的20年赌注的方向是引领AI的下一个趋势,还是走上了错误的道路?
LeCun正处于风暴中心,亲自出现!
录像中,他介绍了V-JEPA 2的新进展,旨在开发一种可以改变AI与物理世界互动技术的世界模式。

可以看出,LeCun对Meta刚刚发布的这个博客真的很用心。

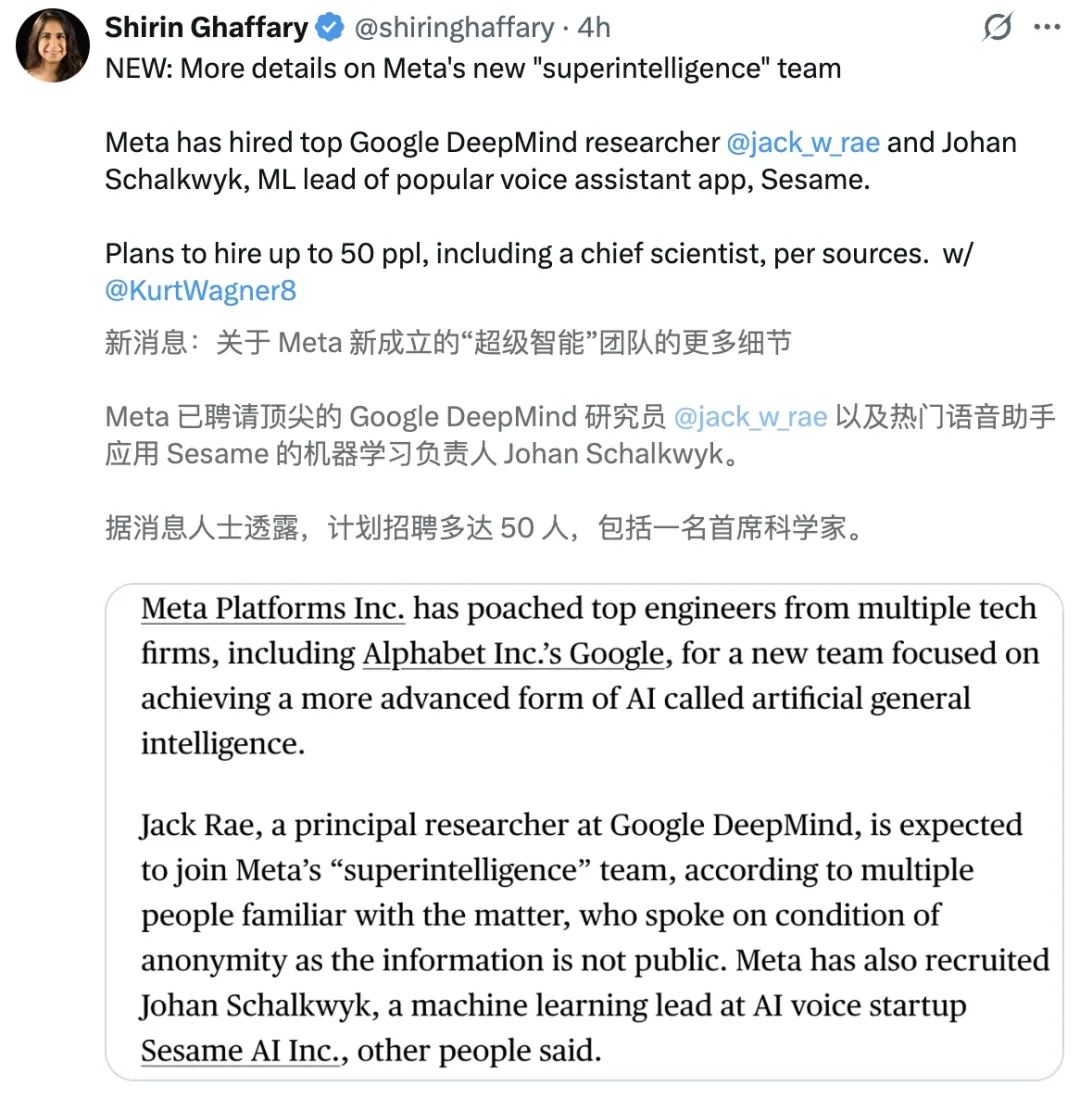
最近,Meta要建立「超级智能」Alexandrr,新团队,巨资挖角 Wang、全力冲击AGI的消息,闹得沸沸扬扬。
如今,Meta也被曝出,它提供了数千万美元的年薪,并挖出了谷歌DeepMind首席研究员Jack。 Rae,与此同时,Sesame也在招募AI语音初创公司 Johan的主管Johan Schalkwayk。
所有的迹象都表明:LeCun似乎要坐在小扎那里的冷板凳上?
就在这一口,LeCun亲自出现介绍V-JEPA 第二种行为,无疑是极其重要的。
世界模型真的能走通这条路吗?与其他大科技企业相比,LeCun更像是在这条目前非常非主流的路线上走自己的路。「孤勇者」。
没有人知道前面的路是什么。
LeCun曾经透露过:「通过训练系统对视频中即将发生的事情进行预测,了解世界如何运行的想法是非常古老的。我至少以某种方式讨论了20年。」
LeCun也曾在今年3月的2025美国数学会联合会议演讲中说过,他折腾了20年,终于发现——
运用自回归预测的思路,训练LLM这样的生成式架构,来预测视频下一步会发生什么,是不可能的。
今天Meta的V-JEPA 二是20年磨一剑的效果。
V-JEPA 2登场!
刚刚,Meta宣布:V-JEPA 2正式发布!
这是第一个基于视频训练的世界模型,不仅具有先进的视频理解和预测能力,而且首次实现零样本规划和新环境下机器人的自主控制。
它的发布,代表着Meta实现高级机器智能化 (AMI) 以及建立一个可以在物理世界中运行的有用AI智能体的目标,迈出了下一步。
这也是LeCun的一贯想法:在我们走向AMI的过程中,构建一个能够像人类一样学习世界、规划未知任务、灵活适应变化环境的AI系统尤为重要。

V-JEPA 2有12亿参数,这是2022年首次提出的。Meta 预测结构的联合嵌入(JEPA)构建。
以前的研究表明,JEPA 它已经在图像和3D点云等模式中表现出色。
V这次发布-JEPA 基于去年发布的第一个V-JEPA视频版本,进一步提升了视频版本。动作预测和世界建模能力,使机器人能够与之相处不熟悉的物体和环境互动并实现目标。
与此同时,Meta也同步发布三个全新的标准评估集,在视频中帮助评估模型的世界理解和推理能力。
网民:期待三年后的AGI
对于V-JEPA LeCun的支持者2的发布,一如既往地表示赞赏。
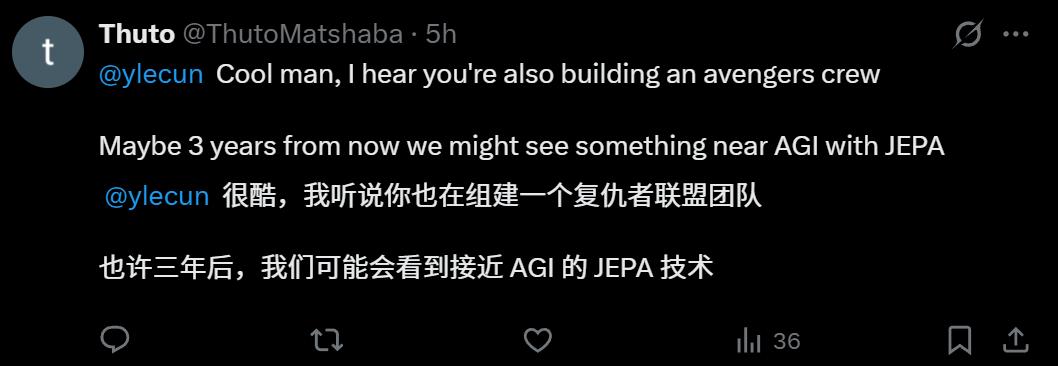
「听到了,你也在建立一个复仇者联盟?三年后,我们可能会看到JEPA技术接近AGI。」
有人说,V-JEPA是你最喜欢的算法名称之一,请务必继续。
有人问过那个敏感的问题:小扎会不会辞退你?还以为你已经离开Meta了…
还有尖锐的评论表示,V-JEPA似乎只是视频中使用的另一个基本模型,没有专有技术?Meta和Scale AI重组,Meta目前的AI政策是否失败?

世界模型是什么?
LeCun在自己的视频中再次解释了世界模型的概念。
如果把网球扔到空中,重力会使它落回路面。如果它在空中旋转,突然转向另一个方向,或者自发地变成苹果,那就太神奇了。
这种物理直觉不是成年人经过多年的教育才能获得的。在句子表达不完整之前,孩子们已经通过观察周围的世界来发展这种直觉。
预测世界将如何回应我们的行动或他人的行动,是人类一直在使用的能力,尤其是当每个人都计划采取什么行动以及如何应对新情况时。
举例来说,当我们穿过陌生拥挤的人群时,我们会朝目的地移动,同时尽量避免撞到沿途的其他人和障碍物。
在打冰球的时候,我们会滑向冰球即将到来的位置,而不是它现在的位置。
做饭的时候,我们会想,要让锅在火焰上停留多久,或者是否应该减少热量。
我们之所以能有这些直觉,是因为我们对世界的内在模型。它还充当了一个内部模拟器,这样我们就可以预测假设行为的结果,然后根据我们认为最能实现目标的方式来选择最好的行动。

我们将利用自己的世界模型,在付诸行动之前,想象隐藏的后果。
所以,如果我们想建造能力的话「三思而后行」AI智能体,最重要的是让它们学会具备以下能力的世界模型。
理解:世界模型应能理解对世界的观察,包括对视频中物体、动作和运动的识别。
预测:世界模型应该能够预测世界将如何进化,如果智能体付诸行动,世界将如何改变。
规划:基于预测能力,世界模型应有利于规划实现特定目标的动作序列。
所以,如何通过世界模型,让AI智能体在物理世界中进行规划与推理?
Meta主要通过视频训练世界模型V-JEPA 2。
之所以使用视频,是因为它是丰富世界信息的重要来源,而且信息很容易获得。
V-JEPA 两个阶段的训练细节
V-JEPA 2是一个基于「预测结构的联合嵌入」(JEPA)建立时间模型,即通过视频数据,学习物理世界的运行规律。
不同于传统的AI模型,通过自我监督学习,可以从视频中学习,不需要大量的人工标记。
其核心部件包括:
· 编码器:输入原始视频,导出嵌入观察世界状态的有用语义信息。
· 预测器:输入视频嵌入和关于预测内容的额外前后文本,导出预测嵌入。
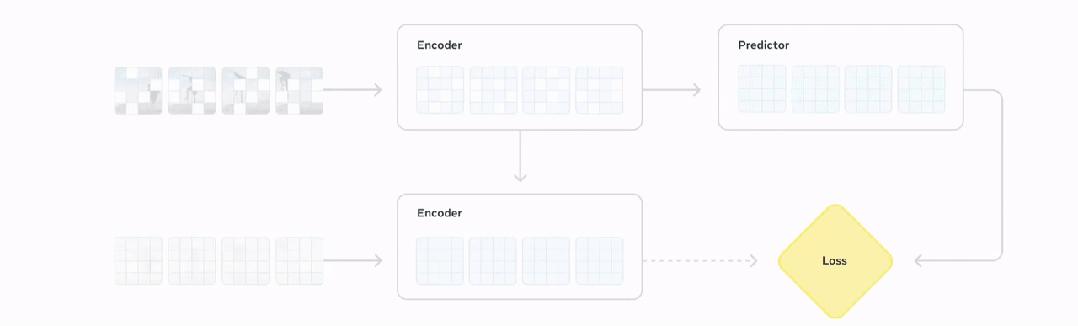
具体来说,V-JEPA 2练习分为两个阶段,逐步让模型从模型中走出来「理解世界」到「改变命运」。
第一阶段:无动作预训练
V-JEPA 2使用超过100万小时的视频和100万个图像,包括丰富多样的视觉信息。
这使得模型学习了很多关于世界运行模式的知识。
它包括,每个人如何与物体互动,物体在物理世界中的移动方式,以及物体之间的相互作用。
通过预训练,V-JEPA 2展示惊人的能力。
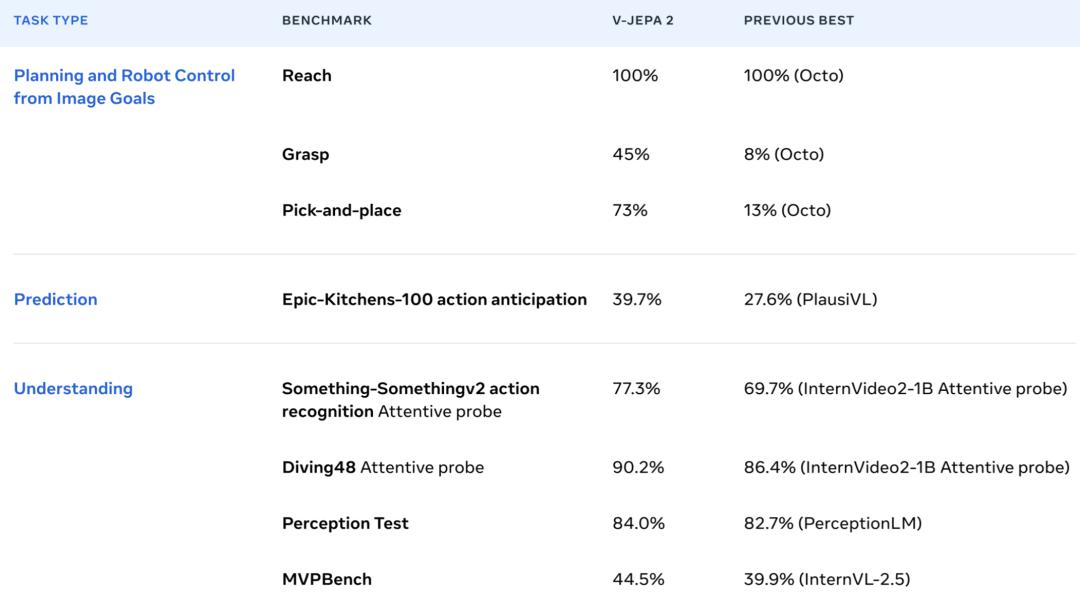
举例来说,Something动作识别任务。-Something 在v2中,它通过轻量级的注意机制表现出色。
类似地,注意力读取器是通过训练冷冻编码器和预测器的特性来训练的,V-JEPA 2在Epic-Kitchens-在100动作预测任务中,SOTA被刷新。

它可以从第一人称视频中计算出未来一秒钟将要执行的动作。
结合语言模型后,它还进行了Perception等视频问答基准测试。 在Test和TempCompass中,创造了最新的记录。
第二阶段:动作条件训练
第一阶段训练结束后,V-JEPA 2虽然可以预测世界可能的演变,但是这种预测并没有考虑到智能体将要采取的行动。
所以,Meta在第二阶段的预训练中增加了机器人数据,包括视觉观察(视频)和机器人执行的控制动作。
通过向预测器提供动作信息,研究人员将这些信息纳入JEPA训练过程。
在练习了这些额外的数据之后,预测器学会了在预测过程中考虑特定的动作,并且可以用来控制。
令人惊讶的是,机器人数据只需62小时,V-JEPA 2学会根据实际行动进行预测和计划。
精确的计划,机器人「即插即用」
V-JEPA 2最令人兴奋的应用之一是零样本机器人规划。
传统的机器人模型,通常需要练习特定的机器人和环境,而V-JEPA 2则不同。

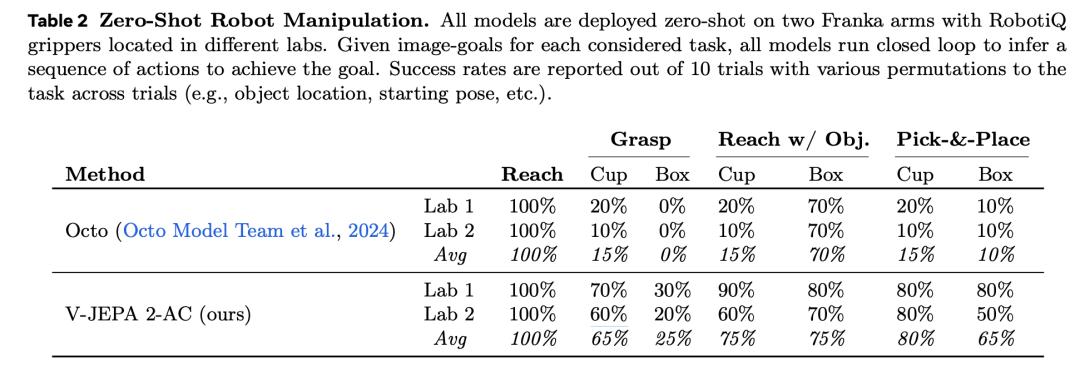
基于开源DROID数据的练习,可以直接部署到实验室的机器人上。
举例来说,它可以完成抓取、捡取物体、放置到新的位置等任务。

对简单的任务,例如捡起或放置物体,V-JEPA 2通过图像指定目标。
该模型采用编码器嵌入当前状态和目标状态,机器人通过预测器进行预测。「想象」根据不同的动作结果,选择最接近目标的动作。
这种「模型预测控制」使机器人的每一步都更加聪明。
而且对复杂的任务,比如捡起来,放在正确的位置,V-JEPA 2通过一系列视觉子目标引导机器人,类似于人类的视觉模仿学习。
新环境中,V-JEPA 新物体采集和放置的成功率为65%–80%。
三大「物理理解」基准测试
另外,Meta团队还发布了三个全新的基准测试,用于评估当前模型从视频中理解和推理物理世界的能力。
IntPhys 2
IntPhys 二是对初期IntPhys标准的升级,灵感来自于认知科学中幼儿学习直觉物理的方法。
其采用「违反预期范式」,通过游戏引擎生成视频对:两个视频在某一点之前完全一致,之后其中一个会发生违反物理规律的事件。
模型的任务是识别哪个视频不合理。
在各种场景中,人类几乎可以达到100%的准确度,而目前的视频模型表现几乎取决于随机猜测。

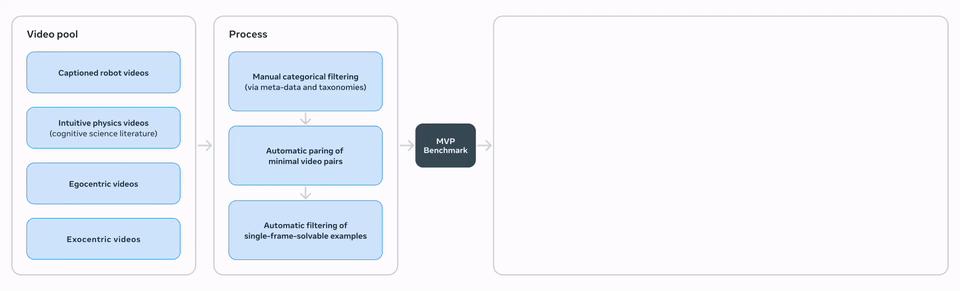
MVPBench
通过多选题,MVPBench测试了视频-语言模型的物理理解能力。
不同于其它视频问答标准,它是专门设计的「最小变化对」——两个视觉上几乎相同的视频组合了相同的问题,但答案却相反。
只有当模型同时回答正确的问题时,才能得分,从而避免了依靠表面视觉或文本线索的分数。「捷径」解法。
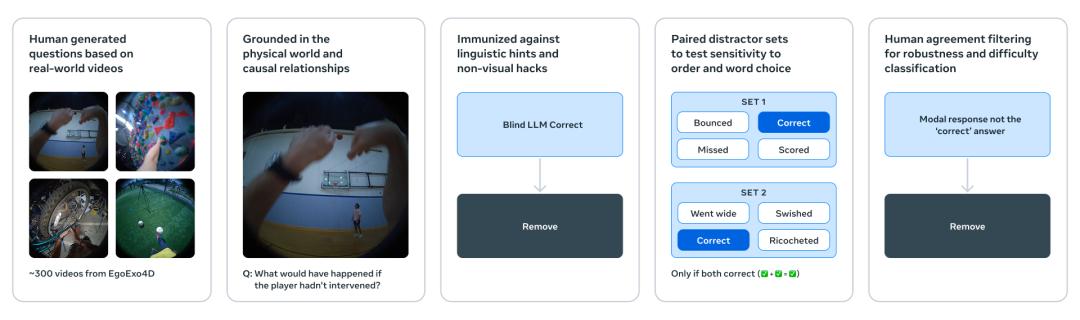
CausalVQA
CausalVQA致力于测试模型对物理世界因果关系的理解,包括三个问题。
主要包括,反事实(如果…会发生什么)、预测(下一步可能会发生什么)和计划(下一步应该采取什么行动来实现目标)。
研究表明,描述多模态模型。「发生了什么」时间表现还不错,但是在预测中「本来可以发生的事情」或「下一步会发生什么?」那时候,与人类还有很大的差距。
下一步:通向高级机器智能!
对世界模型而言,Meta将从多个角度进行深入探索。
目前,V-JEPA 二是只能在单一的时间尺度上进行学习和预测,但是现实中许多任务需要跨越多个时间尺度进行规划。
例如「装洗碗机」或是「烤一个蛋糕」,这样就需要把整个任务分解成一系列的小步骤。
所以,Meta将重点研究分层的JEPA模型,使其能够在不同的时间和空间规模上进行学习、推理和规划。
另一个重要方向是开发多模式JEPA模型,这样不仅可以通过视觉预测,还可以结合听觉、触觉等多种感知实现更全面的世界理解。
参考资料:
https://ai.meta.com/blog/v-jepa-2-world-model-benchmarks/ https://x.com/AIatMeta/status/1932808881627148450
本文来自微信微信官方账号“新智元”,作者:Aeneas 桃子,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com