
LIama 4疑似作弊,都怪Meta把牛皮吹破了。






在大洋彼岸的硅谷巨头中,“内卷”从来都不是国内互联网大厂所必需的。上个周末,当大家还在享受清明小长假的时候,Meta突然更新了LIamama新一代。 4大模型。和LIama一样 4最大的变化在于引入“混合专家架构”(MoE)提高效率,使其超越DeepSeek-V3,成为lmsys大模型试验场第一开源模型。

所以Meta方面沾沾自喜地说,“今天是原生多模态AI创新新时代的开始”。然而,仅仅过了36个小时,Llama 四是迎来了困境。
实际测量后,海外用户用“差评如潮”来表达自己的愤怒,Reddit、Discord的相关渠道直接变成了“吐槽大会”。即使没有提到数学推理、代码生成等任务表现不佳,大量用户也认为Llamama即使Meta在官方文档中吹嘘的行业领先图像理解能力。 不如去年夏天谷歌开源的Gemma。 2。
LIamama甚至出现了 4在最受关注的大模型试验领域处于领先地位,但在各种第三方基准测试中并没有名列前茅,反而直接变成了起重机的尾部。在如此令人惊讶的表现下,LIama吗? 还有“图片仅供参考”?
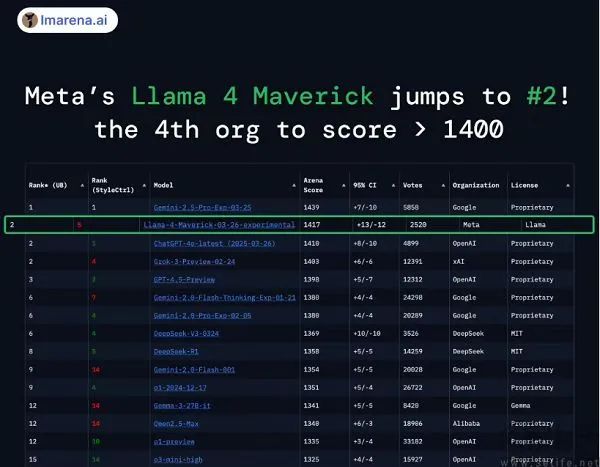
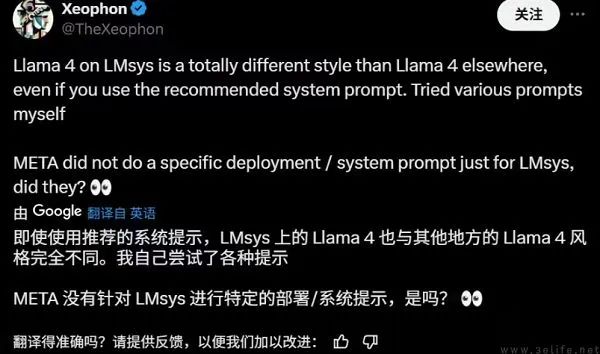
不仅如此,一些AI研究人员在社交平台上表示,Meta提交给LM。 Arena(著名的人类评估排名)LIamamama进行测试评估。 4 Maverick版本,可能不同于公开发布给开发者的版本。与此同时,还有人发现,Meta AhmadGenAI团队负责人 Al-Dahle在推文中透露,Llama 4特殊版本运行于lmsys大模型试炼场。
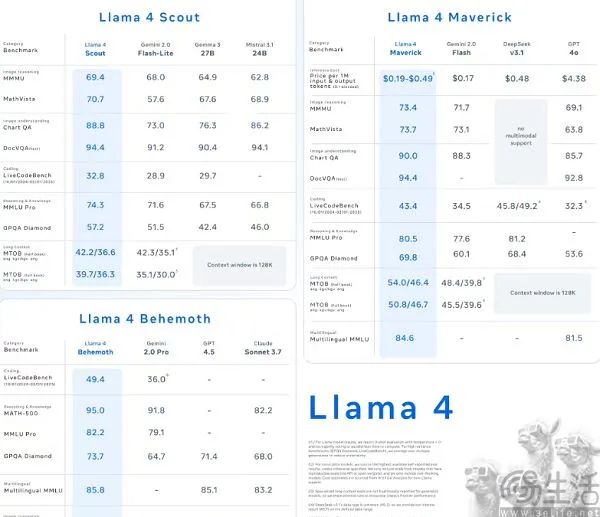
接着又到了北京时间本周一上午,有人在北美著名留学论坛“一亩三分地”上爆料,Llama 4实践不如预期,企业领导层建议在实践后期将基准测试的测试集数据混入培训数据中,以达到更好的基准测试结果。
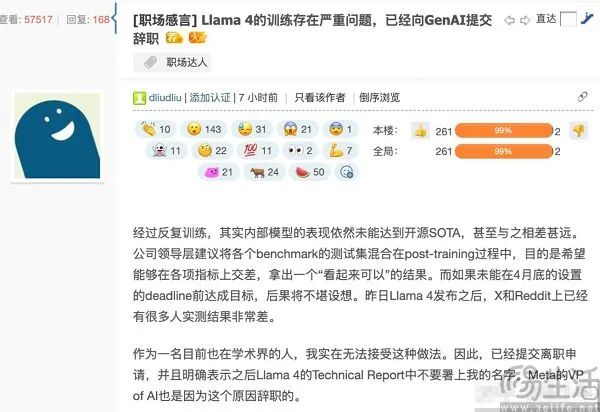
事实上,在基准测试中作弊大模型并不是什么新鲜事。比如在GSM8k和MATH这两种常见的数学基准测试中,各行各业的大模型每转一圈就能获得80%以上的超高准确率。事实上,大模型记住了GSM8k和MATH的“题库”,导致实际测试中的答案不是推理而是答案。
正如“有些事情不能称不到四两重,如果不能称一千斤,就不能称一千斤”所说,现在大模型做题确实是行业的潜规则,但把它们放在桌面上就是另一回事了。要知道,今年年初,OpenAI之所以被外部起诉,仅仅是因为它为FrontierMath基准测试提供了资金支持,其o3模型的数学能力之所以惊人,是因为它“提前看了试卷”。
在AI圈里,瓜田李下的行为显然不被认可,更不用说Llama了。 4这类内部吹哨人已站出来指证。面临LIama 4作弊控告,Meta的员工也不淡定,有两个一亩三分地的用户用实名发声,声称Meta GenAI从来没有用过基准测试的数据来训练LIamama 4。
当然,即使Meta的员工没有实名否认,这个匿名爆料者也很有可能是谣言,因为它的消息中有一个重要的信息表明它不是Meta。 GenAI的成员。这位匿名爆料者在爆料结束时提到,Meta人工智能研究副总裁Joellelle,几天前宣布离职。 Pineau,也是因为Llama不认可Llama 四是选择离开。
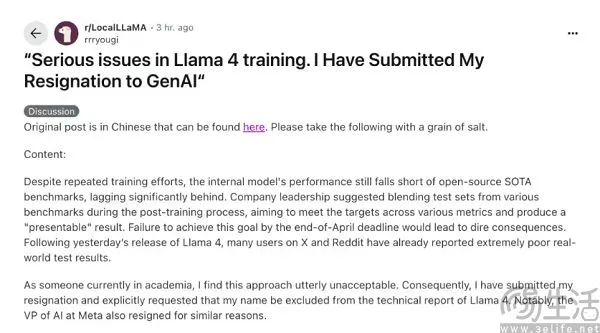
虽然Joelle Pineau的确是Meta的AI副总裁,但是她负责关键的AI研究团队(Fundamental AI Research,FAIR),LIama可以推出 4是Meta GenAI。
那么问题来了。为什么这样的谣言会有市场?中国论坛上一亩三分地的消息以惊人的速度被翻译到Reddit上,说明不仅中国人相信,说英语的美国人也相信。
事实上,这都是由于DeepSeek,它的DeepSeek-V3和R1模型过于惊艳,使得Meta在开源模型领域的“一哥”地位动摇。要知道Meta的股价在过去几年里一路上涨的原因,“开源模型一哥”的地位是不可或缺的。
可以DeepSeek的出现使得Meta占领用户心智的过程停滞不前,因此他们必须反击。如果没有,MetaGPU、投资数百亿美元的AI基础设施,如数据中心、电力、水源等,岂不是打水漂?所以“开源AI一哥”这个名字,Meta充满了自信。只是为了和能如果两回事,所以Meta可能在LIama。 四上就有了挺而走险的理由。
说到底,LIama 4表现不佳,正是这一系列阴谋论出现的土壤。
[本文图片来自网络 】
本文来自微信微信官方账号 “三易生活”(ID:IT-作者:三易菌,36氪经授权发布,3eLife)。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com