
O1金牌团队揭秘AI超越人类惊人时刻!22分完整视频全公开









【新智元指南】OpenAI团队的诞生是一个极具革命性的时刻。在22分钟的完整版采访视频中,他们分享了自己对新模型的探索和背后的发展故事。
OpenAI 完整版的o1团队采访视频,终于上线了!
全程22分钟,o1R&D部门在工程Bob 在McGrew组织下,共同分享「啊哈」时刻。
有人提到,全新的o1模型相当于多个博士。「合体」而且成功,通常比人类的表现要好。还有人说,o1发布后,AGI显然会到来。
「AGI的未来在数学、编码、围棋、国际象棋等方面的表现超过了人类,AGI的未来变得更加清晰。」。

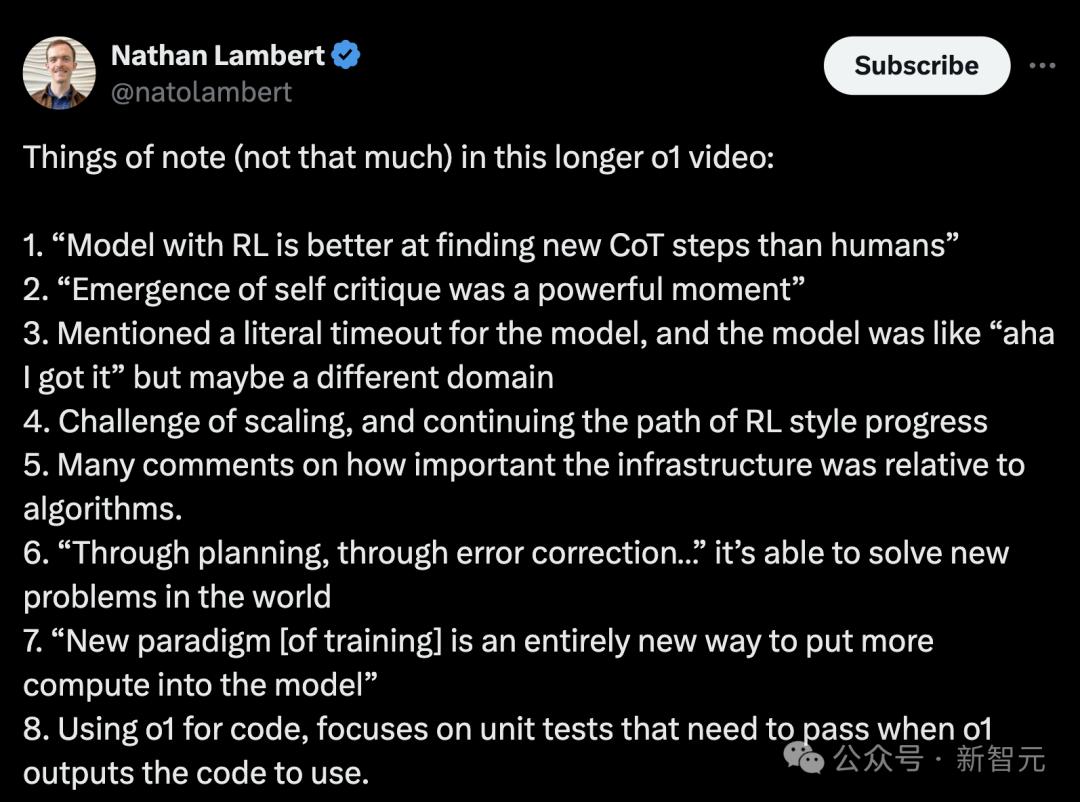
来自艾伦研究所的科学家Nathan 对于这段视频,Lambert做了一个精彩亮点的总结。
一共有8点:
1 加强学习加持o1,比人类更善于发现新的CoT推理步骤。
2 自我分析的出现,是o1最强大的时刻。
3 让o1「超时」之前完成答案,然后突然有了答案。「啊哈」时刻
4 测试scaling参数的规模,并继续沿着强化学习算法的道路进步。
5 许多人提到,与算法相比,基础设施有多重要?
6 o1可以通过规划、纠正错误来解决世界上的新问题
7 新的训练范式是一种全新的方法,可以在模型中投入更多的算率。
8 在编写代码时,当其导出要使用代码时,需要通过单元测试。
下一步,具体来说,o1模型的创作背景。
强化学习 思考,o1开启新的范式
OpenAI作为一个全新的OpenAI系列,与GPT模型最大的区别在于推理。
本质上,它是一种推理模式,即比过去更重要。「思考」得更多。
对于OpenAI研究者来说,「思考」这是最直观的推理方式之一。
有时候,当被问及意大利首都是什么问题时,我们几乎不需要思考,马上就能得到答案。但有时候,当涉及到商业计划书、小说等人物时,需要一个长期的思考过程。
毫无疑问,思考的时间越长,结果就越好。
所以,推理就是把思考时间转化为最佳结果的能力。
用Mark Chen的话说,推理是一种「原语」,这是实现任何可靠思考过程的唯一途径。
关于推理的研究,OpenAI其实很早就开始了。AlphaGo在成立之初就通过RL算法击败了人类的潜力,并进行了大量的研究。
举例来说,他们在2016年开放了游戏测试平台。「Universe」,它是一个开源平台,训练AI通用智能水平。
2018年打造一个名叫OpenAI Five游戏AI,成功击败了世界冠军OG队两届DOTA2国际邀请赛。

同时,在数据和机器人领域,scaling取得了重大进展。
OpenAI团队便开始思考:如何在一般领域加强学习,实现非常强大的AI?
这是GPT系列启动的全新范式。在扩大无监督学习方面,它取得了惊人的成绩。
而且,也就是从那以后,科研人员就开始探索如何将这两种模式结合起来——加强学习和无监督学习。
研究人员表示,这项努力开始的确切时间点,很难说,但是这件事已经进行了很长时间。
「啊哈」时刻
录像中,有人说,自己认为研究中最酷的就是那个。「啊哈」时刻了。
在某一特定的时间点,研究出现了意想不到的突破,一切突然变得非常清晰,仿佛理解了一般的灵光。
所以,团队成员各自经历了什么?「啊哈」时刻呢?
有人说,他觉得在训练模型的过程中,有一个关键时刻,那就是当他们倾注了比以前更多的计算率,他们第一次生成了一个非常连贯的CoT。
此时此刻,大家都惊喜交加:显然,这个模型与以前的模型有着明显的不同。

也有人说,当考虑到训练一个有推理能力的模型时,首先想到的就是让人类记录自己的思维过程,从而进行实践。
对他来说,啊哈时刻是当他发现CoT的效果甚至比人类写的CoT还要好的时候,通过强化学习训练模型来生成和提高CoT。
这个时刻表明,我们可以通过这种方式来扩展和探索模型推理能力。

这个研究人员说,他一直在努力提高模型解决数学问题的能力。
令他非常沮丧的是,每一次生成结果之后,模型似乎从来没有质疑过自己做错了什么。
但是,在训练其中一个早期的o1模型时,他们惊讶地发现,数学测试中模型的分数突然显著提高。
而且,研究人员可以看到模型研究过程——它开始反思自己,质疑自己。
他惊叹地说:我们终于做出了不同的事情!
这是一种非常强烈的感觉,那一刻,仿佛一切都聚集在一起。

另一位研究人员说,当你要求模型时,「超时」在完成思考之前,过程很有趣。
正如自己正在参加数学比赛一样,任何思考都是有时间限制的。
他指出,这也是他进入AI领域的主要原因,而现在,对自己来说,也算是完成了。「闭环」时刻。

另外,o1模型令人惊叹的是,它对科学发现和工程进步有很大的帮助。
对许多人来说,AGI似乎是一个非常抽象和遥不可及的概念。只有当你亲眼看到AI在人类擅长的事情上做得更好时,你才能相信AGI的到来。
对于专业的国际象棋和围棋手来说,IBMDeep Blue,以及DeepMindd AlphaGo和AlphaZero,在几年前,他们就意识到了这一点。
对于这群擅长数学和编码的OpenAI科学家来说,o1模型也有类似的含义。更有意思的是,他们的工作相当于创造了一个可以压倒自己能力的AI。
在项目中,遇到了什么困难?
对于遇到的障碍,科研人员直接表示,LLM的训练从根本上来说是一件很困难的事。
类似于从地球发射到月球的火箭,成功之路只有很窄的一条,但是失败之路数不胜数,稍微偏离一个角度就达不到目标。
有成千上万种方法可以在训练过程中出现问题,即使在这群才华横溢的研究科学家手中,每一轮训练也会遇到数百个问题。
另外,随着模型变得越来越智能化,例如o1就相当于拥有几个phd学位的人,评估也变得越来越困难。
有时候,他们需要花很长时间来确定模型是否正确,最终很多常用的行业标准趋于饱和,需要重新找到适合o1能力的基准测试。
除模型开发过程外,研究人员还被问及他们最喜欢的o1模型用例。
Hyung Won Chung表示,o1可以是一个很好的编码助手。
在工作中,他通常遵循TDD。(Test-Driven Development)开发方法,在o1的支持下,可以避免自己编写单元测试工作,而是直接指定需求,让模型自动编写。
另外,报错信息也可以直接扔给o1。虽然有时候问题不能直接解决,但是可以帮助你解决错误,而不是编译器。

Jason Wei说,他经常把o1当成头脑风暴的伙伴,可以讨论的问题范围相当广泛,从如何解决机器学习问题到如何制作博客或文章。

今年5月,他写了一个关于LLM评价的博客,参考了o1的建议,比如文章的结构、各种评价标准的优缺点、写作风格等等。

工作OpenAI是一种怎样的感觉?
对这一问题,许多人都在谈论每个人的智慧,以及团队氛围的和谐。
比如我调整了一个星期的代码,被路过的同事瞬间解决了;每天和极其聪明的同事相处,让自己逐渐变得谦逊。
Mark 描述Chen「草莓」这个项目很棒「有机」(organic)这个项目,因为每个人在专业问题上都有自己的看法和想法,都有满怀热情想要推广的想法。
如果这些想法聚集在一起,就会产生火花,像滚雪球一样越滚越大。
然而,独立的另一面是,每个人都坚持自己的观点,但并不固执。如果他们看到客观的结果来反驳自己的观点,他们也会改变主意。
更值得称赞的是,这群极其聪明的人,同时也很好,愿意帮助别人解决问题,同事们一起吃饭,一起出去玩,让很多采访中的研究人员直言不讳。「这是一次很好的工作经历。」。
o1-mini创作背景
o1-mini发布的动机是为更多的研究者提供一个预算较低但推理能力仍然很强的模型。
这是可以称之为的「推理专家」,它比过去最好的OpenAI模型更聪明。
而且,成本和延迟都很低。
或许,它可能并不一定知道一个名人,因为他的出生日期,但是它确实具备了如何进行有效的推理,以及大量的智慧。
OpenAI研究人员表示,算法将进一步改进,使其能够与最佳小型相媲美。
此外,全世界的研究人员一直在投入更多的计算和硬件,这使得模型成本在很长一段时间内呈指数级下降。
但是,一个缺点是,我们没有花更多的时间去寻找一种新的方法来扭转局面。
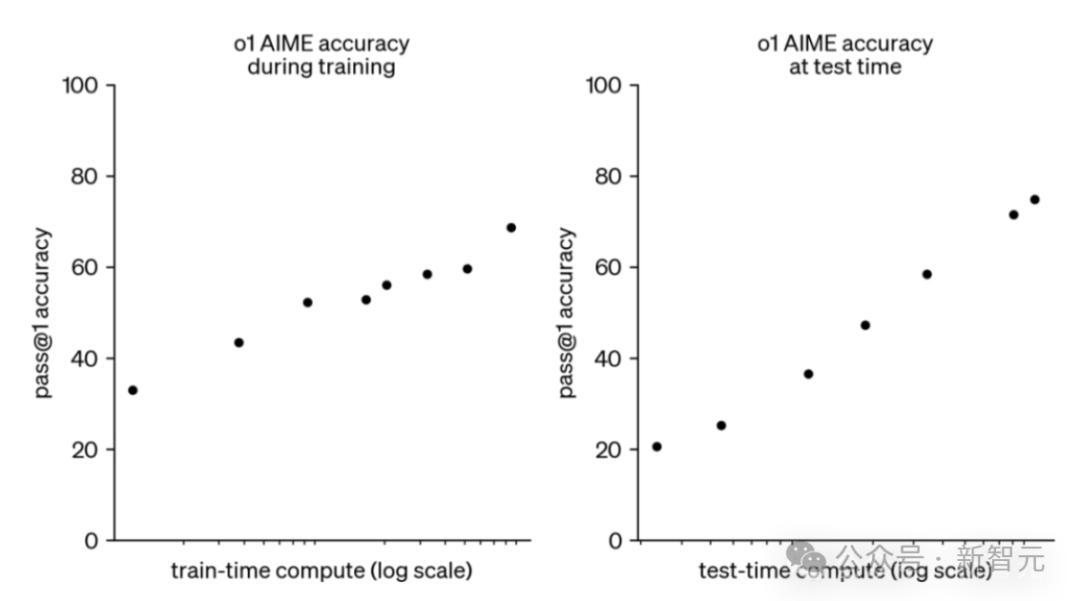
o1新范式,就是我们的发现-推理scaling,也可以很好的提高计算效率。
什么是进行研究的动力?
这批「智慧大脑」能够聚在一起,究竟是什么原因,激励他们去做研究?
一位研究人员说,一想到自己用不同的方式,让模型实现推理,这个过程简直太迷人了。
也有人说,「苦尽甘来」。
o1可以快速回答,这是长期思考问题的模式的第一步。未来,我们将需要几个月甚至几年的研究来走向下一段旅程。
「想到我们少数人能带来改变世界的影响,我们非常兴奋,有意义。」。

最吸引人的是,新范式解锁模型之前无法完成的任务,不仅仅是回答一些查询,更是通过规划和纠正错误,泛化出新的能力。
即使是o1也能带来新的知识,对科学发现来说,这是最令人兴奋的部分。
研究人员表示,在短期内,模型将成为自我发展和越来越强大的推动者。
最后,当o1负责人问,「还有什么其它观察值得一提吗?」?
Jason Wei共享道,「一个有趣的观察是,每个训练出来的模型都不一样,有自己的爱好,就像手工艺品一样。这种独特性为每个模型增添了一点个性」。
参考资料:
https://x.com/OpenAI/status/1837194684428345474
本文来自微信微信官方账号“新智元”,编辑:桃子 经授权发布的乔杨,36氪。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com