
闭卷开考全国一卷,AI大模型高考数学全部不及格?!








电子爱好者网报道(文章 / 周凯扬)目前的大模型不仅实现了商业化,还开辟了一条新的“赛博斗蟋蟀”跑道,用各种评价标准测试了大模型在英语、数学、推理和代码方面的综合成绩。高考作为中国最权威的考试之一,是对学生综合能力最具代表性的考验。大模型这种特殊身份的考生,如果报名参加高考会取得什么样的成绩,也引起了网友的好奇。
大模型评估系统上海人工智能实验室 OpenCompass 最近举行了这样一次测试,让我 6 大型开源模型和 GPT-4o 参加一次特别的“高考”,但是这些大模型所取得的成绩却让很多人大吃一惊。
全国一卷闭卷开考
这次大模型报名参加高考,OpenCompass 第一轮检测采用全国新课程标准 I 作为试卷的来源,试卷覆盖江苏、浙江、河北、福建、山东、湖北、湖南、广东等省份。为了方便测试,除了省略其他非统一学科外,英语也被省略了。 30 分听,所以它的单科总分变成了 120 分。
为实现“闭卷”,在这些被测模型中,包含 Mistral 开源对话模式 Mixtral 8x22B、零一万物的 Yi-1.5-34B 大模型,智谱 AI 的 GLM-4-9B、由上海人工智能实验室推出 2-20BInternLM2-WQX 阿里巴巴的大语言模型和 Qwen2-57B 和 Qwen2-72B。
上述开源模型的开源时间都在本次高考之前,最新的发布日期是 InternLM InternLM22专门在高考前夕推出的文曲星系列模型-WQX。即使是这样,它也是发布的 6 月 4 每天的时间也满足了闭卷考试的前提。唯一的例外是商业闭源模型 GPT-4o,但是它的成绩也只是作为评价的参考。
阅卷评分方面,OpenCompass 邀请了一批有阅卷经验的高中老师对主观问题的答案进行评分,每份试卷至少由 3 教师批阅均分,甚至对分差较大的题目进行了二次审批。另外值得注意的是,为了保证阅卷者在主客观题上产生“主观臆断”的观念,OpenCompass 阅卷后才告诉阅卷者答案是由大模型产生的,并对结果进行整体分析。
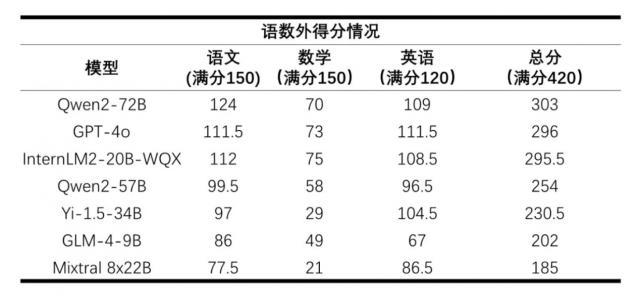
AI 大模型高考语数外评分 / 上海人工智能实验室
就总分而言,阿里巴巴的通义千问大模型 Qwen2-72B 排在第一位,其次是成绩相似的。 GPT-4o 和 2-20BInternLM2-WQX。但是单从数学这门学科来看,所有的大模型都不合格,Mixtral 8x22B 甚至只有得到 21 分的成绩。
语言能力仍然是 LLM 强项,但“考试”能力仍有提升空间。
许多大型模型都在这次“高考”中取得了良好的语文和英语成绩,尤其是在英语试卷上,GPT-4o 更加用英语获得了 111.5 得分高。在语文方面,国内模型更具优势,尤其是在文言文阅读、古诗阅读、名句默写等方面。
有趣的是,在语文作文中,各大模型也没有拉开较大的差距。但根据上海人工智能实验室的分析,大模型作文倾向于将“第一”、“第二”、“第二”等表达顺序的词放在段落的最前面。另外,目前大部分大模型还没有提高一些“考试”题型。比如在语文考试中,大模型还不能完全理解阅读理解中的一些自身、比喻、隐喻等概念。因此,在语言和文字的应用问题上,比如补句,一般分数都不高。
但是在英语考试中,虽然各大模型整体表现不错,但是有些模型并不适合非常规的问答题,比如完形填空、七选五,答案会出现错位,所以得分率还是处于较低水平。
在英语续写和作文的编写中,大模型忽略了题目要求,一般都是超过字数限制而扣分,单段文字太长。在故事续写的问题中,一些大模型也会有不切实际的联想,比如 2-20BInternLM2-WQX 答案中,出租车司机拨打银行内线电话的离谱情节就出现了。
数学不及格,主观问答成了最大的短板。
AI 各种题型的大模型数学评分 / 上海人工智能实验室
与语言能力测试成绩相比,AI 在数学能力评估中,大型模型所取得的成绩并不令人满意。最高分为 2-20BInternLM2-WQX 取得的 75 分数,可以说在数学这门课上,绝大多数大模型都是溃不成军。全国新课标 I 卷数学试卷中有两个带图的问题。对于不支持多模式输入的大模型,只能选择输入题目文字,然后放弃图片,这也是丢分严重的原因之一。
Qwen2-72B 带图题的答案 / 上海人工智能实验室
以上图中带图题的答案为例,大模型只给出了一个答案框架,并没有给出具体值的答案。GPT-4o 和 2-20BInternLM2-WQX 等待大模型虽然给出了具体的答案和解决问题的过程,但最终得到的却是一个错误的答案。
之所以 2-20BInternLM2-WQX 能够在数学考试中取得较高的成绩,也得益于其团队在数学模型上的积累。今年初 InternLM 数学模型书生已经发布 · 浦语数学(InternLM2-Math)。书生 · 浦语数学也是第一个支持正式数学语言和解题过程评价的开源模型,不仅可以用于数学计算和解答,还可以用于数学基础研究和教学。
即便如此,在数学考试的问答和讨论问题上,大模型仍然取得了惨淡的成绩。这是因为大模型的答案大多比较乱,常见的错误答案也很多,但答案是正确的。因此, 77 在满分问答上,最高分 2-20BInternLM2-WQX 还只是得了病 26 分。
AI 大型考生是否不合格?
根据阅卷人的评论,AI 大模型还是比较“死板”的考生,尤其是论述题。以语文论述题为例,很多大模型在第一步就失败了,所以答案无关紧要。在英语题目中,大模型的实力是毋庸置疑的,但在题型和作文中还是会有遗漏。
对于数学来说,它仍然是所有大模型的弱点。大模型更像是记住公式但不能使用的学生。大多数问题倾向于穷举而不是推理。对于带图的三维几何答案,大模型缺乏空间概念,导致答案过程和答案离谱。从这个角度来看,大模型的“考试”能力还是欠缺的,但是在快速迭代下,我相信这个障碍在未来会越来越少。
阅读更多热门文章
加关注 星标我们
把我们设为星标,不要错过每一次更新!
喜欢就奖励一个“在看”!
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com