
谈数据工程6-数据架构









这个部分,我们将讨论数据架构。
内容:1. 数据架构2是什么?. Lambda vs Kappa 架构3. 实际项目
一 什麽是数据架构?
数据结构是信息系统的蓝图,服务于商品的业务需求,描述如何收集、存储、转换和分发数据。它由数据模型、治理策略、规则和标准组成,需要实施和遵循,从而构建一个强大而安全的信息系统。
资料结构必须满足信息系统的业务和技术要求。
项目需求下列内容可能包括:1. 减少数据交付延迟2. 根据需要自动扩展数据交付33. 增加不同类型数据的数据模型的灵活性4. 提高数据质量和一致性5. 降低存储成本和支持提高6. 提供可靠性和 GDPR 等待标准合规
支持业务的技术需求包含:
1. 最佳业务案例数据库和摄入工具2. 数据仓库解决方案3高效检索和存储优化. 定义数据关联和消费的转换逻辑4. 设计分析推理平台展示平台 KPI5. 采用云服务进行分布式计算,确保6个不同团队的最低成本和访问限制. 为了遵守法律法规,维护数据的完整性,制定安全管理和监控系统。
下面是数据架构师职责简述:
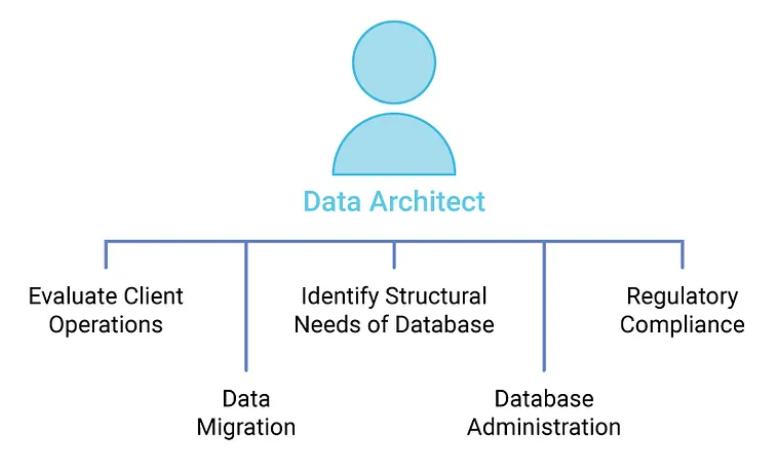
它是数据架构师和数据工程师两者的区别:
二 Lambda 与 Kappa 架构
Lamba 架构它被定义为具有即时和批处理能力的组合。它有 3 层:即时层,用于使用。 Storm 或 Flink 等待服务处理传递到流程;批处理层用于使用 Hadoop 或 Spark 等待服务批量处理历史数据;服务层,提供批量处理和实时组合视图数据。例如,在电子商务业务中,客户(批号)的消费历史记录需要了解预算和质量限制,并且需要立即浏览数据以提出适当的建议。
Lambda 架构面临的问题是,您需要将预处理和其他常见工作复制到即时层和批处理层,因此建议使用相同的服务进行这两种提取,例如 Spark,这有助于完成这两个操作。
Kappa 架构的介绍的目的是采用统一的方法来应对这个挑战,而且只有一个流层, Apache Kafka 等待服务处理所有操作。首先,它可以在消息传输引擎中实时动态存储,并可以存储在分析数据库中进行批量检索,或者通过服务层根据查询类型提供与消息传输引擎的实时互动。
Kafka 它是一种快速、容错、水平可扩展的服务,具有以下许多特定功能,因此主要用于实现。 Kappa 架构。
尽管 Lambda 维修和运营成本较高,但 Kappa 使系统更简单。但是为了建立 Kappa 为了保证可靠性和准确性,需要不断优化结构。
所以,一般而言,当有大量或多个数据无法实时处理时,就会使用。 Lambda 在需要传入的流数据的情况下, Kappa 当中等数据立即付诸行动时,会更倾向于 Kappa 结构。数据具有高度一致性,因此不需要过多的质量校准或复杂性。
Kappa 一个实际的例子是存在的 Uber 与 Kafka 共同实现:
三 实际项目 电动汽车基础设施分析
它是一个已经实现的具体项目及其数据架构:
问题阐述:对电动汽车充电基础设施进行分析,以识别任何方法并提出改进建议。数据库:Open Charge API数据编排:Airflow数据湖:AWS S3 存储对数据结构的理解:AWS Glue Crawler and Data Catalog数据清理与预处理:AWS LambdaETL 以及探索工具:AWS Glue 和 Athena数据库及仪表板:Snowflake数据安全:IAM
澄清:我仅在 AWS 和 Snowflake 免费套餐服务在中间使用。在我看来,当所有服务都在 AWS 里时,明白为什么要用。 Airflow 而不是 Glue ETL 也许令人费解——这只是成本因素。
我在这里免费试用,所以有一些限制,但是如果你比较舒服,适合你的用例,你可以用。 Glue Studio 进行 ETL 与仓库连接!
我仅使用 Glue Crawler 和 Data Catalog 等 Glue 对数据进行服务探索,使用 Athena 运行 SQL 查询确保有正确的结构。如您查看代码库,您可以找到和找到它。 Snowflake 连接是通过 SQL 查询而不是 Glue。
Open Charge API
这个数据库包含了各种有关电动汽车充电站的信息,你可以使用经度和纬度来查询这个区域的电动汽车充电站。
Airflow — ELT
用来安排数据管道,并根据不同区域定期摄取API数据。
AWS Glue
AWS Glue 用来理解数据架构,通过存储元数据的爬网过程和数据目录。也可以使用 通过Glue Glue Studio 进行相关的数据转换,然后将其加载到其中 Snowflake 在数据库中。也可以定义 Lambda 函数调用的 ETL 操作或者调度它。数据质量检查也可以在ETL操作中进行。
AWS Lambda
它用于清理和预处理原始数据,并将中间结果存储在清理后的另一个S3存储桶中。每次将新数据加载到原始数据中。 S3 储存桶内时,都能触发。
AWS Athena
可以用 Athena 执行 SQL 查询了解数据,并将查询记录存储在分析数据库中,以便浏览数据库。
Snowflake data warehouse
该分析存储用于终端用户(数据分析师),用于了解趋势和方法,并构建仪表板向相关利益相关者展示。
AWS IAM
身份和访问管理允许您设定不同的定义。 AWS 资源密钥管理的作用和策略。您需要定义以上每一个。 AWS 资源角色可以相互交互。
总之,使用 Airflow 从 API 进行摄入,当 S3 当目标事件发生时,存储桶会触发 Lambda,如果有可用的清洁对象,可以使用。 Snowflake 触发载入。
仪表板在Snowflake中的
找出可用设备的总数。
选择前10名ev_table 个“locationtitle”、“quantity”,其中“quantity” > 1 order by “quantity” desc;
2. 找出不同电流类型的功率分布特征
SELECT sum ("powerkw") as "total_power","currenttypeid" FROM ev_table where "currenttypeid" > 1 GROUP BY "currenttypeid" ORDER BY "currenttypeid" ;
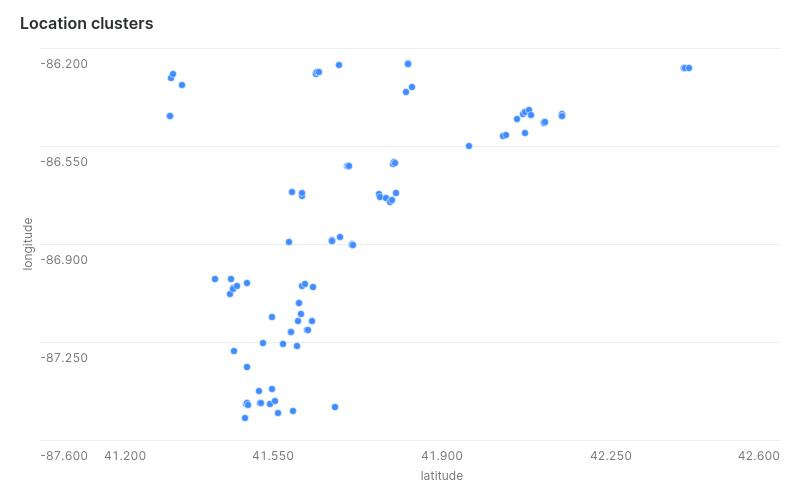
找出电动汽车站的地理邻近性
从ev_table中选择“纬度”、“经度” ;
找出不同等级充电能力之间的功率分布。
按下ev_table组中的“levelid”挑选“levelid”、sum(“powerkw”);
5. 根据充电能力等级了解位置分布。
按下ev_table组中的“levelid"选择记数(""locationtitle”)、“ levelid”
6. 找出功率最高的位置
选择前10名ev_table 个 “locationtitle”、“powerkw”,其中“powerkw” > 0 order by “powerkw” desc;
本文来自微信微信官方账号“数据驱动智能”(ID:Data作者:晓晓,36氪经授权发布,_0101)。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com