
ICLR 2026统计公布:中国AI论文占比超半数,清华产量超斯坦福MIT总和






本文来自微信公众号:APPSO,作者:发现明日产品的
如今国际顶级AI学术会议,正在成为中国研究者的主场。
每年AI顶会放榜,各个学术机构都会悄悄比拼论文收录量,但今年ICLR(国际学习表征会议)放榜后,研究员Dmytro Lopushanskyy做了一件格外硬核的事。
他没有直接用现成的官方统计,而是写了足足250条正则表达式,手动下载了ICLR 2026全部5356篇收录论文的PDF文件。

之后,他从每一篇论文的首页提取出作者署名机构,再通过代码规则完成数据清洗和归一化处理,自动把同一机构的不同写法,比如“麻省理工”和“MIT CSAIL”做了合并整理。
为什么不用现成统计,反而要做这种“手工分类”?
因为他发现,常规学术统计平台的数据,都是按照“作者当前所属机构”来统计归属。举个例子:一名在清华大学读完四年博士的研究者,在读博期间完成了一篇高质量论文,毕业后去斯坦福当了教授,系统刷新数据后,这篇诞生在中国的论文,就会被算成斯坦福的学术成果。
开发者已经把原始数据整理上传到Github:https://github.com/DmytroLopushanskyy/iclr2026-affiliations
这种统计偏差,长期以来都低估了中国学术机构的实际贡献,同时虚高了美国的成果数量。Dmytro这次统计的解析成功率达到96%,去伪存真后的真实数据被整理成热力图,才让我们看清了当前全球AI学术的真实格局。
真实数据展现中美AI格局,中国成果超半数
整理后的统计数据,冲击力远超很多人的预期。
热力图中中国大陆机构的占比非常大,本届ICLR收录的论文里,中国大陆机构贡献了43.7%,而美国的占比为31.9%。
如果把中国香港的7.7%也算入中国,本届ICLR超过一半的论文,署名第一机构都来自中国。曾经的欧美学术强区,整个欧洲大陆的总占比只有5.3%,甚至比新加坡一个国家的5.5%还要低。
更值得关注的是具体机构的排名。
今年清华大学以332篇的论文产量,登顶全球单一机构第一名,这个数字是什么概念?斯坦福有177篇,麻省理工有167篇,清华大学一家的产出,几乎等于美国这两大顶尖名校的产量总和。紧随清华之后的上海交通大学、北京大学、浙江大学,也都稳稳站在全球第一梯队。
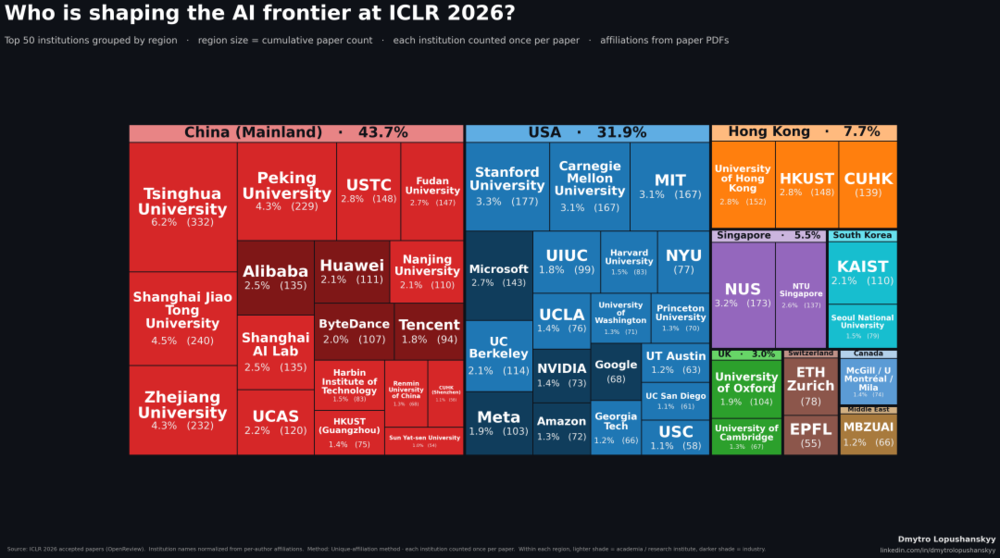

不光高校表现突出,国内产业界的AI科研成果也十分亮眼。
阿里、上海AI实验室、华为、字节跳动、腾讯,这五家中国科技企业和研究机构加起来,一共发表了582篇论文。过去常有声音吐槽中国互联网公司只会做商业模式微创新,不重视底层基础研究,这次ICLR 2026的数据,彻底打破了这种刻板印象。
可以说如今中国AI发展,早就不再依赖个别天才的偶然突破,而是形成了一套精密、庞大、高度体系化的持续研发体系。
不过,在这份亮眼的数据背后,我们也需要看清客观存在的差距。
比如虽然总数量我们已经实现反超,但在仅占总收录量4%的Oral(口头报告,这类论文一般代表最具原创性和启发性的研究方向)论文中,美国机构占比约为40%,中国占比为30%。
我们在工程化落地和规模化产出上已经拥有绝对的规模优势,而美国在开辟全新研究方向上,依然保持着相对领先,这也是当前中美AI发展比较真实的现状。
硅谷科研偏向AGI探索,中国AI实验室更务实落地
如果说热力图是宏观的行业现状报告,那艾伦人工智能研究所(AI2)知名研究员Nathan Lambert在今年5月,对北京、杭州等地AI企业的36小时走访调研,就是一次深入的微观观察。
他走访了智谱AI、月之暗面、阿里千问、美团、小米、零一万物等多家中国AI企业后,回国撰写了一篇关于中国AI实验室的内部观察文章,在硅谷引发了大量讨论。他发现了中国大模型能和美国形成抗衡的核心逻辑:极低的组织内耗,以及极度务实的研究者群体。
文章链接:https://www.interconnects.ai/p/notes-from-inside-chinas-ai-labs
在Lambert看来,美国顶级实验室普遍存在一个明显的问题:研究者个人自我意识太强。
训练大模型是极其复杂的系统工程,从数据清洗、分布式通信优化到强化学习对齐,每个环节都需要团队成员互相配合妥协。但在硅谷,很多知名研究员都有强烈的个人偏好,不愿意让步。
有传闻说Meta的Llama团队就曾经因为技术路线分歧出现动荡,核心研究者各自坚持自己的方向,都想把模型往自己主导的方向推进。反观中国的AI实验室,Lambert发现这里的研究者格外务实。
研究者们不会纠结谁的方法听起来更高级,所有人的目标都高度一致:只要能提升模型的某项指标,再枯燥琐碎的工作也有人愿意做,这种务实性把团队的内耗降到了最低。
Lambert还总结了这种文化带来的具体优势:团队更愿意做不起眼的基础工作提升模型整体效果;新人没有经历过过往AI炒作周期,能更快适应最新技术路线;个人意识弱,组织架构可以比较平稳地扩围;同时拥有大量能在现有方案基础上攻坚突破的人才储备。
更让Lambert惊讶的是,在美国顶级实验室里,实习生通常只能接触边缘项目,但在中国,在读硕士和博士可以深度参与核心大模型的研发工作。Lambert敏锐地指出了这种模式的核心优势:没有历史路径依赖。
大模型的技术路线迭代速度非常快,资深科学家往往会受过往研究的路径依赖影响,认定自己研究了十几年的老方法才是正确方向,但中国年轻研究者不一样,只要有数据证明新路线效果更好,他们可以立刻放弃旧方案,快速切换赛道。
值得一提的是,Lambert发现中国AI行业内部的氛围比外界想象的更和谐,各家实验室私下交流都充满尊重,所有中国实验室都认可字节跳动和它的豆包模型,因为字节是中国少有的站在技术前沿,同时坚持闭源研发的机构。同时几乎所有实验室都认可DeepSeek,认为它是研究判断和执行水准都非常顶尖的团队。
这次调研里还有一个细节值得关注:在硅谷,顶尖AI研究员不只是工程师,很多还会扮演半个“哲学家”的角色,他们喜欢在播客上讨论“通用人工智能AGI会不会在2030年毁灭人类”,频繁探讨AI安全和伦理边界这类宏大命题。
于是Lambert也试探着询问中国AI研究者,对AI的经济影响和长远社会风险的看法,得到的不是长篇大论的讨论,反而是普遍的困惑——这类“AI毁灭人类”的宏大命题,目前并不在他们当下的工作范围内。
这种对空泛宏大叙事的“不关心”,反而成了一种竞争优势,减少了团队在哲学讨论上的内耗,让所有脑力都集中在工程落地和指标突破上。
在中国的AI实验室里,导师、博士生和企业工程师之间形成了极短的反馈回路。
这种模式打破了学术界和工业界之间的壁垒,正如Nathan Lambert观察到的:这种低内耗的组织模式,让中国AI拥有了极快的推进速度——只要方向确定,就能依靠密集的智力投入快速抹平技术差距。
当然,这套模式在当前的发展阶段非常有效,但随着规模扩张的红利逐渐见顶,下一阶段AI发展的核心壁垒,终究会回到“原始创新能力”的较量上。
到那个时候,高密度的人才协同网络,和敢于打破现有框架的原创者,会是AI发展下半场缺一不可的两个关键。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com