
京东云“龙虾天团”亮相 首次开源通用基础大模型









3月24日,京东技术团队正式发布京东云“龙虾天团”:基于JoyAI大模型打造的OpenClaw(昵称“龙虾”)轻量云主机一键部署、一体机、云上SaaS版等产品,以及CodingPlan大模型套餐包同步推出。
据京东团队数据,“龙虾”系列产品上线后,近一周token调用量环比飙升455%。

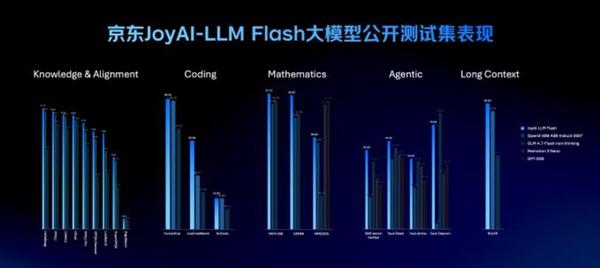
与此同时,京东首次开源通用基础大模型JoyAI-LLM Flash的Instruct版本。该模型参数量达48B,激活3B参数,性能测试结果优于GLM-4.7 Flash(non-thinking)等同规模模型。
开源地址:
https://huggingface.co/jdopensource/JoyAI-LLM-Flash-Base
https://huggingface.co/jdopensource/JoyAI-LLM-Flash
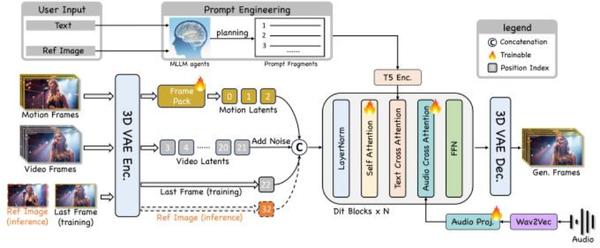
数字人领域,京东自研JoyAvatar数字人视频生成框架正式发布。该框架通过双教师DMD后训练、动态CFG调制、历史帧+伪帧专属模型结构三大创新技术,解决了文本控制薄弱、多模态控制信号冲突、长视频生成能力不足等行业痛点,性能已超越Omnihuman-1.5、KlingAvatar 2.0等国际SOTA模型。

具身智能方面,京东透露将成为全球最大的具身智能数据公司。计划一年内积累500万小时人类真实场景视频数据,两年内积累超1000万小时优质数据,同步完成100万小时采集机器人本体数据积累,并建成全球规模最大、场景最全的具身智能数据采集中心。
01.龙虾一体机上线 轻量云主机预置OpenClaw镜像
目前,京东云已在轻量云主机中预置OpenClaw应用镜像,支持三步快速部署,开发者无需手动搭建运行环境。最新数据显示,京东云OpenClaw云服务用户规模单周增长超300%,云端部署需求持续攀升。

针对中大型企业的OpenClaw部署需求,京东云推出OpenClaw一体机,具备三大核心优势:零代码开箱即用,3分钟即可投入使用;原生融合开源生态;支持官方持续更新。
OpenClaw一体机提供三种硬件规格:
标准版型号1:满足数据安全合规要求,支持超80人同时使用,日均处理Tokens超10亿。
标准版型号2:面向追求高模型精准度与并发能力的中大型企业,兼顾性能与隐私,支持50人同时使用,日均处理Tokens达5亿+。
个人版:实现本地闭环运行OpenClaw及模型,适合5人及以下团队使用,日均处理Tokens3.5亿+。
02.通用基础大模型开源 引入“纤维丛”数学工具
京东此次开源的JoyAI-LLM Flash Instruct版本,参数量48B、激活3B参数,在公开测试基准上表现优于GLM-4.7 Flash(non-thinking)等同规模模型。
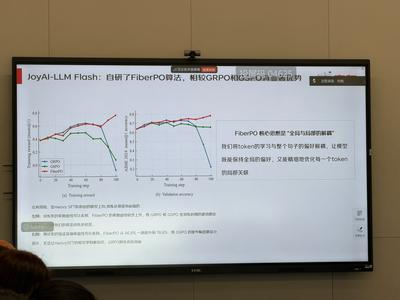
算法层面,JoyAI-LLM Flash将几何流形学中的“纤维丛”数学工具引入强化学习,提出创新强化学习技术——FiberPO。
在保持3B激活参数的前提下,该模型通过动态稀疏路由提升计算效率,稀疏比例优于GLM-4.7-Flash等模型。
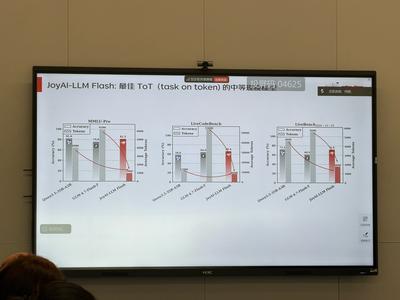
代码辅助方面,基于稀疏优化与训推协同技术,JoyAI-LLM Flash的响应速度超越同级小参数量模型,支持程序员“边写边调”。通过预训练与多轮微调,模型对编程语法、多语言适配(如React/Vue)及代码逻辑的理解精准,生成代码可直接复用。
智能体应用上,JoyAI-LLM Flash能低成本快速适配复杂业务场景。目前,京东JoyAI大模型技术已在2000+场景落地,融入京东“超级供应链”,内部运行的智能体数量超5万个。
03.数字人框架达商用级 唇形同步等指标领先
京东自研的JoyAvatar数字人视频生成框架,在分布匹配蒸馏(DMD)后训练框架中引入音频、文本双教师模型,实现“音视频同步”与“文本控制”的分离监督、融合学习。无需新增训练数据,即可将通用视频大模型的文本可控性迁移至数字人模型,让数字人精准响应复杂动作、镜头交互等指令。
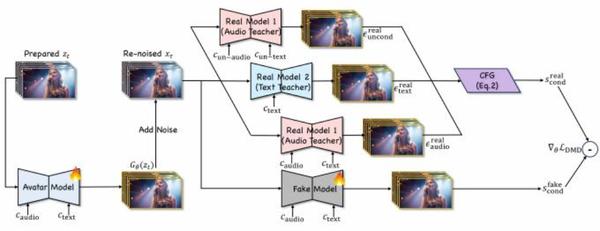
该框架根据视频生成的去噪时间步,动态调整文本、音频的无分类器指导尺度:生成早期优先通过文本控制信号确定动作框架,后期则优先依据音频信号确保唇形同步。
借助Frame pack历史帧编码模块与伪最后一帧策略,框架构建专属长视频生成模型结构,突破传统数字人模型“生成时长短、帧闪烁、身份漂移”的限制,支持30秒以上长视频生成,且全程保持身份稳定、动作流畅。
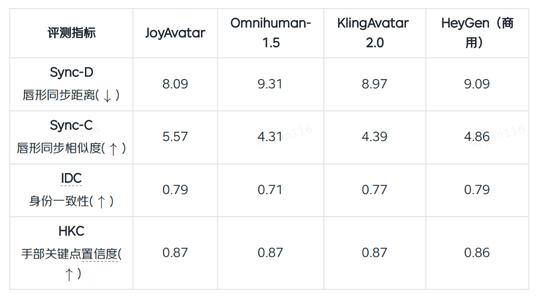
客观评测显示,JoyAvatar在唇形同步、身份稳定与动作自然度上达到商用标准。其中唇形同步相似度Sync-C达5.57,高于Omnihuman-1.5、KlingAvatar2.0及商用模型HeyGen;手部关键点置信度HKC为0.87,保障肢体动作自然流畅。
JoyAvatar可快速落地于电商服务、智能客服、内容创作等核心场景:
京东内部场景:数字人主播(支持直播间复杂动作、多主播互动)、智能客服(多角色智能问答)、京东云生态(为客户提供数字人技术底座)等;
通用产业场景:影视动画(快速生成卡通人物/非人类主体视频)、线上会议(虚拟分身多轮对话)、教育科普(虚拟讲师复杂动作演示)、文旅文创(数字文旅形象定制)等。
04.JoyInside开发平台上线 提供一站式智能硬件方案
京东推出的JoyInside面向硬件终端提供智能化适配能力,支持拟人化交互与多人群适配。2026年初,该能力新增社交玩法并升级语音合成技术,与京东京造联动搭建跨品类智能硬件互联体系,实现设备互通,还扩展至八大方言识别交互。目前,JoyInside已接入近百家家电家居品牌、超40家机器人及AI玩具厂商。
此外,京东推出“JoyInside开发平台”,提供低代码可扩展环境及“搭建环境+AI能力+硬件模组+产业资源”的一站式解决方案:
面向大众与设计师:提供可视化工具与即插即用模组;
面向开发者:支持定制与外部Agent集成;
面向厂商:通过便捷API助力老硬件低成本智能化升级,并对接京东零售渠道与营销资源。
05.结语:完整技术栈加速AI规模化落地
依托累计超1700亿元的技术投入,京东已构建从京东云算力底座、JoyAI系列基础模型,到智能体、数字人、具身智能的完整技术矩阵。这一立体化布局不仅推动京东内部海量业务场景的智能化升级,更通过开放生态加速AI从技术突破走向普惠应用。
本文来自微信公众号“智东西”(ID:zhidxcom),作者:王涵,编辑:冰倩,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com