
决定AI产品存亡的关键:产品经理的这一核心决策









不少产品经理将精力倾注于功能交互与算法选型,却忽略了一个更底层的问题:产品设计能否产生'有价值的数据'?这才是AI产品真正的护城河所在。
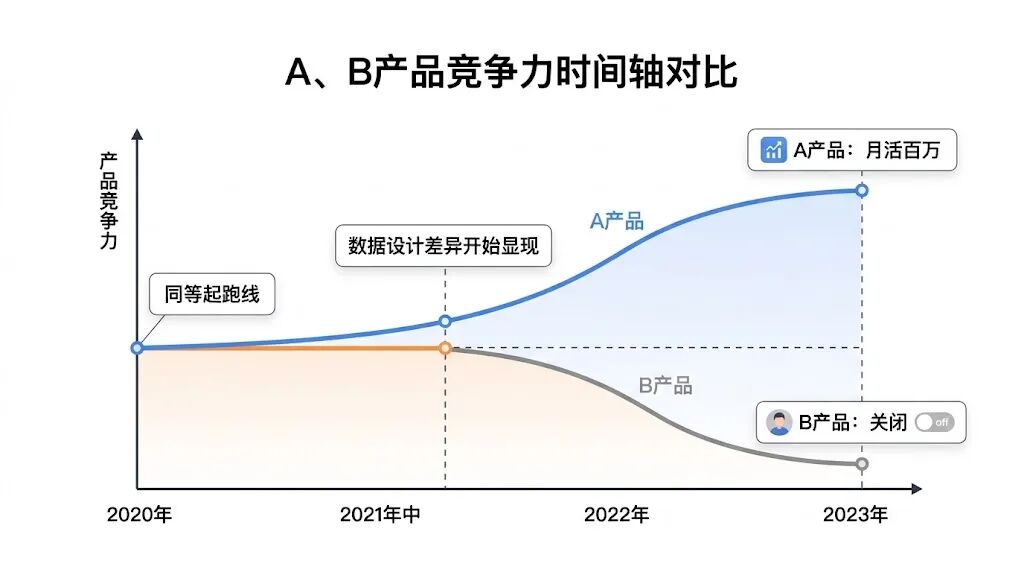
两款相似AI产品,三年后命运迥异
2020年,国内几乎同时出现了两款AI智能简历助手,暂且称它们为A产品和B产品。
两款产品起点相近:均为帮助求职者优化简历、匹配岗位的AI工具,初期用户量、融资规模不相上下,背后算法团队实力也旗鼓相当。
三年后,A产品成为行业头部,月活突破百万,还孵化出招聘SaaS业务;B产品却悄然关闭,几乎未引起任何关注。
是A产品的算法更优吗?并非如此,初期两者均采用同类开源模型。
是A产品更擅长市场推广吗?也不是,B产品曾一度比A产品更为激进。
核心差异,源于产品设计的一个决策。
A产品在设计之初就明确:简历优化工具最具价值的数据,并非'用户投递了多少份简历',而是'哪些简历修改行为对应了后续的面试邀请'。于是他们将产品设计成闭环:用户投递简历→跟踪后续面试结果→记录哪些修改带来正向反馈→反哺推荐模型。
B产品的数据埋点逻辑则较为传统:关注'用户打开次数、使用时长、功能点击率'。这些数据能优化交互,却无法让模型更智能。
A产品积累的是有因果关系的训练数据,B产品积累的是无闭环的行为日志。三年间,这一差距被无限放大。
这个案例让我意识到:AI产品的竞争,在设计阶段就已决定胜负。那个关键变量,便是——数据设计。
什么是'数据设计'?多数PM从未深入思考
'数据设计'并非数据分析、埋点方案或BI报表。
它指的是:在产品功能设计阶段,有意识地规划该功能将产生何种数据、这些数据是否具有训练价值、能否形成壁垒。
打个比方,你是厨师要做菜。数据分析是'分析菜是否好吃';数据埋点是'在厨房装摄像头';而数据设计,则是'建厨房前规划食材来源、储存与加工方式'。
多数PM会做前两件事,却很少认真对待第三件。
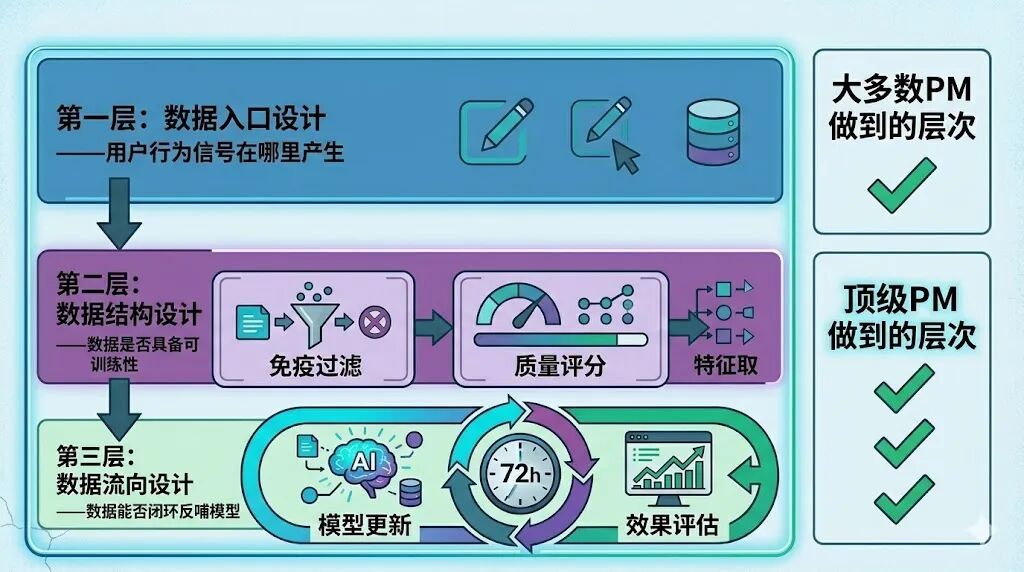
数据设计有三个核心层次,PM必须清晰思考:
第一层:数据从何而来(数据入口设计) 产品功能是否会产生有意义的用户行为信号?用户哪些操作能反映真实需求与判断?
第二层:数据形态如何(数据结构设计) 采集的原始数据是否具备可训练性?是有标签还是无标签?稀疏还是稠密?
第三层:数据流向何处(数据流向设计) 这些数据最终能否回流模型形成反馈?还是仅躺在数据库中闲置?
三层都考虑清楚,才是完整的数据设计。只做其中一层,是多数PM的现状。
三个影响产品命运的数据设计决策
数据设计并非抽象理念,它体现在产品经理日常的功能决策中。以下三个决策点,决定了AI产品数据壁垒的高度。
决策一:产品是'询问用户',还是'让用户行动'?
这是数据设计最根本的分歧点。
'询问用户'指通过调研问卷、评分弹窗、满意度打分获取数据。这类数据看似直接,却有两大缺陷:一是用户表达与真实行为常不一致;二是数据量少,难以驱动模型迭代。
'让用户行动'则是将数据采集嵌入用户自然操作流程,用户每一次使用行为本身就是数据。
以AI代码助手为例,GitHub Copilot的数据设计十分巧妙:不仅关注'用户是否接受建议',还追踪'用户接受后5分钟内是否修改'。若接受后立即修改,说明建议质量低;若直接提交,则质量高。这个行为序列为模型提供了精准的质量信号,且用户无需额外操作。
这便是'让用户行动'的精髓:数据采集隐藏于用户价值中,用户无感知,每一次操作都是高质量标注。
决策二:设计的是'单次反馈',还是'序列反馈'?
很多PM设计数据采集逻辑时,仅考虑'单次':这次交互好不好,用户是否满意。
但AI模型真正需要的是序列信号——用户行为的前后文关系。
例如,某AI客服产品仅采集'用户是否点击满意',这是单次反馈。
更聪明的设计是采集序列:用户提问→AI回答→用户追问(说明未答好)→AI二次回答→用户结束对话(说明答好)→整个对话链构成训练样本。
前者仅知'结果',后者还知'哪步出问题'。对模型训练而言,后者价值是前者的数十倍。
Netflix的推荐系统是经典案例。他们发现'用户评分'信号较'脏'——反映的是'用户认为应该喜欢',而非'真正喜欢'。因此Netflix更依赖'用户观看行为序列':暂停位置、次日续看、中途关闭等,这些序列信号比评分准确得多。
单次反馈是一个点,序列反馈是一条路。想清楚需要点还是路,决定了能训练出何种模型。
决策三:数据是'可积累的',还是'用完即弃的'?
这个决策决定了产品是否有时间维度的竞争优势。
可积累数据指随时间推移价值持续增长的数据,如用户历史行为画像、专业领域标注语料、长期交互记录。这类数据有'飞轮效应'——积累越多,模型越好,产品越好用,用户越多,数据积累越快。
用完即弃数据指采集后失去价值的数据,如实时流量数据、无串联的单次会话日志、无标签的原始点击流。这类数据可用于运营监控,却无法构筑数据壁垒。
某医疗AI公司是反面案例。他们耗费大量资源采集数百万条患者问诊对话,但因未设计标注体系,这些数据全是无标签文本,几乎无法用于模型精调。数百万条数据价值近乎为零,后来花了比采集更多的成本补标注,白白浪费两年时间。
采集前需思考:这条数据三年后还有价值吗?若答案不确定,大概率是用完即弃的。

数据设计失误的代价:三个真实案例
仅说正面做法不够,再看数据设计失误的惨重代价。
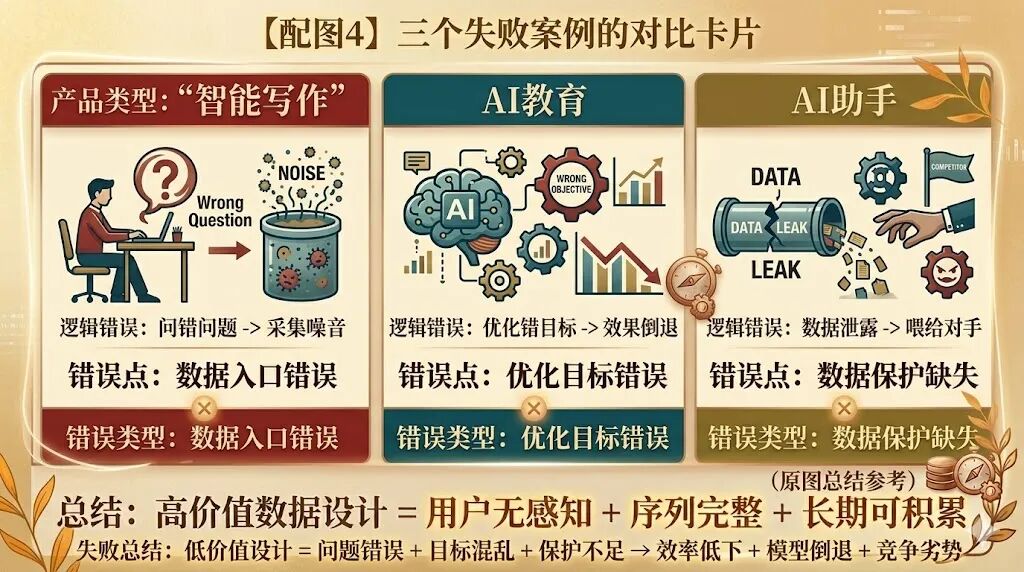
案例一:某智能写作工具
因'问错问题'浪费18个月
该产品上线后设计了'用户评分体系':AI生成内容后弹出1-5星评分。他们用这些评分训练模型18个月,产品质量却几乎无提升。
原因很简单:用户打分依据的是'内容与期待的接近度',但用户往往说不清期待,评分高度随机。更糟的是,评分弹窗影响体验,大量用户跳过,导致数据存在严重选择性偏差——只有极端满意或不满的用户才打分。
他们问错了问题,采集到的是噪音而非信号。
后来转而追踪'用户对生成内容的具体修改行为',三个月后模型质量显著提升。
案例二:某AI教育平台
以'完课率'为核心数据,越优化越糟
该平台用AI推荐学习路径,核心优化目标是'完课率'(用户完成课程的比例)。看似合理,问题却随之而来:模型为优化完课率,开始推荐最简单的课程——因为简单课程完成率高。结果用户虽都完课,但学的是无挑战性内容,学习效果极差,很快流失。
他们采集了正确数据,却优化了错误目标。数据设计不仅要设计'采集什么',还要设计'优化什么'——这两个问题必须同时想清楚。
案例三:某AI助手产品
数据被竞争对手'白嫖'
这个案例特殊却发人深省。某AI助手因产品开放,用户反馈数据(包括对话日志)通过API大量流出,被竞争对手用于训练模型。等他们意识到问题时,竞争对手已用其数据完成一轮模型迭代。
数据设计还包括数据保护设计。辛苦采集的高质量数据,若无良好访问控制,可能成为竞争对手的免费训练集。
PM如何在日常工作中培养数据设计能力?
说了这么多理论与案例,最后回到实际问题:作为产品经理,该怎么做?
第一步:
每次需求评审时,加入'数据维度'的灵魂发问。
评审新功能时,强制自己问三个问题:
'这个功能上线后,会产生什么数据?'
'这些数据能否用于训练或优化模型?'
'若不能,能否调整设计让它产生更有价值的数据?'
将这三个问题作为需求文档的标配章节,初期可能觉得多余,但坚持三个月,对数据的直觉会发生质变。
第二步:
学会区分'行为数据'与'偏好数据',优先设计前者。
行为数据是用户'做了什么'——点击、修改、停留、复购;偏好数据是用户'说喜欢什么'——评分、问卷、标签选择。
绝大多数情况下,行为数据比偏好数据更可靠、更具训练价值。功能设计时,优先思考'如何让用户自然行为成为数据',而非'如何让用户主动告知偏好'。
第三步:
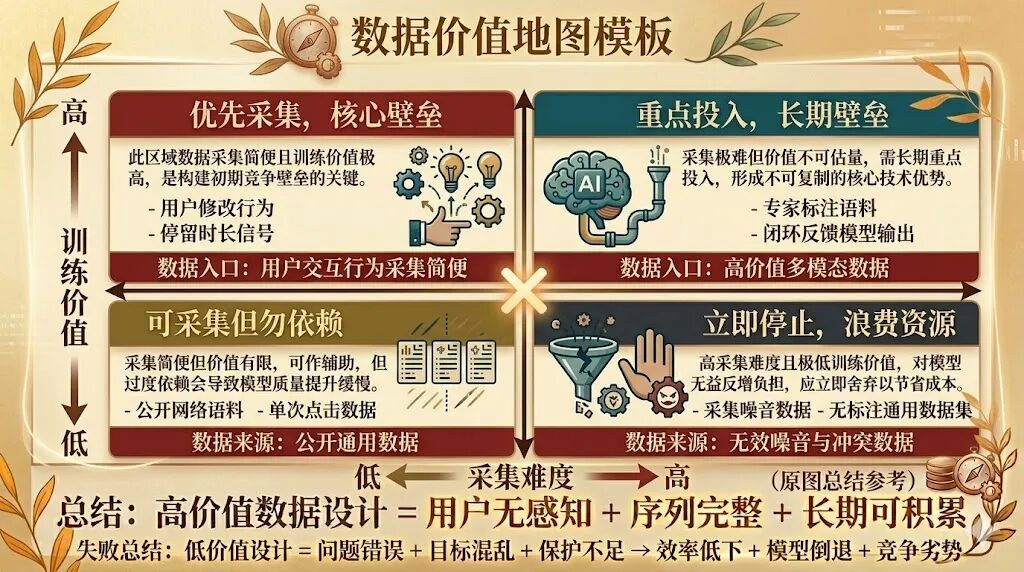
建立'数据价值地图',定期复盘产品采集内容。
每三个月画一张表格:列出产品正在采集的所有数据类型,评估每类数据的'训练价值'(高/中/低)和'积累趋势'(增长/平稳/衰减)。
这张表会带来意外发现:有些数据采集成本高但训练价值低;有些数据易获取却未被利用。定期复盘是提升数据设计能力的最快路径之一。
产品经理:AI产品数据战争的第一决策人
我在做AI产品的几年里,见过太多团队精力用错地方:花数月选算法框架,花大价钱买算力,开无数会议讨论模型架构——却从未认真思考:产品在产生什么样的数据?这些数据能否让产品越来越聪明?
算法工程师可选择更好的模型,数据工程师可优化数据管道,但只有产品经理能在设计阶段决定产品能否采集到有价值的数据。
这是只有PM能做、也必须做好的决策。
AI产品的竞争,本质是数据的竞争。而数据的竞争,在产品经理画第一张原型图时就已开始。
本文来自微信公众号“人人都是产品经理”(ID:woshipm),作者:吴知,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com