
Benchmark:具身智能研究亟待补齐的关键基础设施









这项竞赛的目标并非展示机器人已具备的能力,而是尽可能精准地界定它们暂时无法达成的边界。
这恰恰是产业决策最需要的信息。因此,此次赛事或许不会带来榜单上的狂欢,但必然能帮助研究人员认清技术的真实状况。模型竞赛只是见证技术飞速发展的一个方面,
若ManipArena能持续运行,它记录的将不只是排行榜,更可能成为具身智能迈向产业化的时间刻度。
具身智能模型存在结构性矛盾:一边是迭代迅速的模型,另一边却是滞后的基准线。
也就是说,具身模型始终缺乏科学、可靠的评测标准,难以从发散的“野蛮生长”转向有方向的“向上生长”。
“木受绳则直”,具身模型同样需要科学的Benchmark来精细评估、诊断,甚至指导未来研究方向。但现实是,由于长期缺乏统一、高标准的真机测评体系,模型迭代与产业化进程受到严重制约。
实际上,任何产业从技术探索走向规模化,都会经历从“百花齐放”到“标准收敛”的阶段。
这是多个万亿级市场规模产业验证过的成功路径:互联网时代,协议标准实现全球网络互联互通;深度学习的爆发也离不开评测体系。它们不直接创造产品,却决定着技术进步的方向与速度。
具身智能正处于类似的早期阶段。过去两年,从VLA(视觉-语言-动作)模型到世界模型,技术路径层出不穷,研究范式高度分散。但行业不缺模型,也不缺演示视频,缺的是能回答模型“在真实世界中究竟能达到何种水平”的统一标尺。
没有Benchmark,模型提升多停留在叙事层面;有了Benchmark,技术进步才具备可验证、可复现、可积累的产业价值。
在此背景下,CVPR 2026官方竞赛ManipArena的启动,意义不仅是新增一场比赛,更在于它试图补齐具身智能领域最关键却长期缺位的基础设施——面向真实世界的统一评测体系。

更重要的是,可持续运行的研发平台能不断沉淀数据、验证结论并反哺模型迭代,形成“评测-改进-再评测”的正向循环,推动整个领域从无序探索走向系统进化。
ManipArena:不展示能力,而是测量模型边界
表面看,ManipArena是机器人操作竞赛,但其设计逻辑更接近系统化能力测量。
长期以来,机器人评测依赖仿真环境或精心布置、高度简化的桌面抓取任务。这类基准虽推动算法进步,却难以反映真实世界的复杂性。而真正能还原物理世界的长时序决策、空间移动、多模态感知、不可预测的物理交互,常被排除在评测之外。这导致研发人员只能盲目推进,无法精准迭代,模型可能在实验室表现出色,却难以迁移到现实场景。
ManipArena的核心目标正是填补这一鸿沟。赛事设置20个真实机器人任务,在统一环境下进行真机评测,覆盖推理能力、泛化能力、长时序决策及多模态感知等关键维度。相比过往“简单抓取”测试,这更接近对完整操作能力的系统审视。
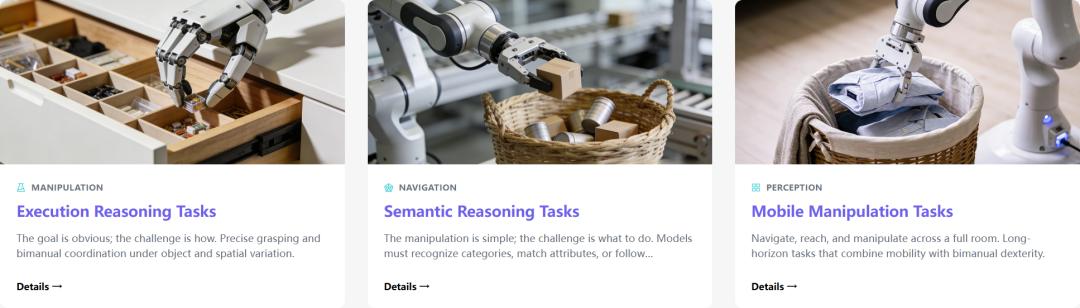
ManipArena赛事在科学设计上投入大量时间。其中重要设计是“一个模型完成全部任务”(One Model for All Tasks):参赛者不能针对不同任务分别训练模型,必须依赖统一策略完成所有挑战。这一规则本质是筛选通用能力,而非单点技巧或任务过拟合。
另一关键设计是分层OOD(分布外)评估。每个任务通过物理属性、空间布局和语义组合等多维变化,构造不同难度等级,从域内变化到语义外推,系统测试模型在未知情况下的表现。这使评测不再仅给出分数,而是呈现能力曲线,揭示模型卡在感知、推理还是执行环节。
此外,ManipArena将评测范围从桌面操作扩展到包含导航与全身控制的移动任务,如整理衣物、挂画、收纳物品等,覆盖更接近真实生活的操作场景。这意味着它不再评估“机械臂技能”,而是评估“具身系统能力”。
换句话说,这项竞赛的目标不是展示机器人已能做什么,而是尽可能准确地界定它们暂时还做不到什么。
这正是产业决策最需要的信息。因此,此次赛事或许不会带来榜单上的狂欢,但必然能帮助研究人员认清技术的真实状况。
从竞赛到研究基础设施:具身智能拐点已至
ManipArena更深远的意义或许在于,它不只是一次竞赛,而是可持续运行的研究平台,具有“常态化评测”“持续性运营”“大幅降低门槛”等特色。
首先,它具备常态化评测能力。参赛者可基于公开数据训练模型,通过远程接口提交算法,由平台完成真机测试并返回结果。这种机制不仅适用于比赛,也适用于日常研究验证,使其成为持续可用的Benchmark,而非一次性活动。
其次,平台提供高质量真实世界数据与精细评测体系,包括188小时高质量真机数据,并承诺未来持续开源数据,为模型训练与分析提供直接支撑。在机器人领域,获取真实数据成本极高,这种集中供给本身就是重要的科研基础设施。
更关键的是,它显著降低参与门槛。研究团队无需购买昂贵机器人设备,仅依托一台GPU服务器即可参与全流程评测。
这是关键转折点:具身智能研究长期受制于硬件成本,只有少数实验室拥有设备优势,多数团队难以开展真实世界实验。远程真机评测机制让更多研究者能参与竞争,扩大创新来源。
额外说明的是,这种统一硬件的方式避免了硬件差异对结果的影响。而且,由于自变量的“量子一号”等硬件设施是AI原生、为模型而生,能更好发挥模型性能。若ManipArena能持续发展,也将有助于形成统一的硬件标准。
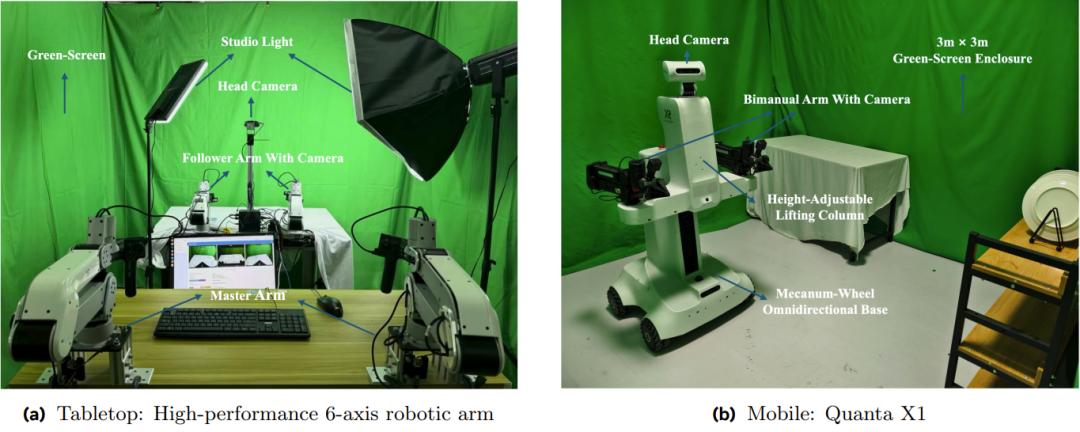
当性能差异主要由算法而非设备决定时,研究重点将更聚焦模型,加速软件层面的竞争与收敛。
“要想富,先修路”,如今具身智能研究要从粗放的野蛮生长走向规范化发展,正缺少这样稳定、科学的基础设施建设。
自变量成为行业变量
外界可能会问,为何是一家模型企业推动这项工作?答案恰在于,只有真正开发过模型的人,才最清楚模型的能力边界与潜在漏洞。
首先要认识到,Benchmark从来不是中性的,它隐含对未来技术方向的假设:
- 例如,ManipArena将推理、长时序决策和多模态融合置于核心位置,实际是对具身智能主流发展路径的判断,是对过去简单任务评测的技术矫正;
- 又如,赛事开源的多维数据特意强调电机电流和关节速度,官方称“电机电流和关节速度可作为力和接触的代理信号,当前主流模型(VLA、World Model)均未有效利用这些信号”,ManipArena针对性开源将有助于推动力敏感策略研究;
- 此外,官方多次强调VLA与世界模型同台竞技,看两者是否各有千秋、孰优孰劣,这在一定程度上也昭示了技术趋势。
其次,做过模型的人更了解模型如何“取巧”。在许多基准测试中,模型可通过统计偏差、环境规律或特定技巧获得高分,却不具备真正的通用能力。ManipArena的设计明显试图规避这些问题,如统一环境、均匀分布变化、跨任务通用模型要求等,都旨在防止过拟合和投机行为。
再次,真正科学有效的Benchmark设计往往来自大量经验积累。只有从零到一全链路自研、踩过足够多坑的团队,才知道模型会在哪里崩溃。从这个角度看,“做题多的人更会出题”并非调侃,而是技术现实。评测体系本质上是对过去研究经验的结构化沉淀,也是对未来技术路径的引导。
作为长期坚持端到端具身大模型路线的企业,自变量深度参与了从VLA到世界模型融合范式的演进,对模型在真实物理世界中的能力边界与失效模式有一手认知。
其自研的WALL-A模型首创将VLA与世界模型深度融合,在统一多模态输入输出架构下引入具身多模态思维链,通过时空状态预测、视觉因果推理与可学习记忆机制,使机器人在非结构化环境中实现更强的零样本泛化能力。同时,依托大规模真机强化学习,模型在持续与物理世界交互中积累高质量经验,自主修复长尾问题,形成“基础模型—真实交互—能力进化”的技术闭环。在此基础上开源的WALL-OSS也表现出优异的长程操作能力、因果推理与空间理解能力。
正是这种从模型架构、训练方法到真实部署的全链路实践,让自变量不仅熟悉模型训练的难点、与模型技术发展同步,也成为具身智能能力评测体系的积极塑造者。对于技术革命而言,福泽社会从不取决于哪家企业的技术强弱,而是从行业沉淀出可靠标尺开始。在具身智能领域,亦是如此。
模型竞赛只是见证技术迅猛发展的一个方面,若ManipArena能持续运行,它记录的将不只是排行榜,更可能成为具身智能迈向产业化的时间刻度。
本文来自微信公众号“具身研习社”,作者:彭堃方,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com