
AIGC检测为何总“看走眼”?腾讯优图揭秘:问题或许源于数据源头






随着AIGC技术的快速发展,一行简单的提示词就能生成高度逼真的内容,但这一技术进步也带来了虚假新闻、身份欺诈、版权侵犯等严峻的安全隐患。AI生成图像检测因此成为AIGC时代不可或缺的基础安全能力。
不过在实际应用中,却存在一个尴尬的现象:检测器在公开基准数据集这类“考场”上表现出色,可一旦应用到全新模型或不同数据分布的“战场”,性能就会大幅下滑。
近日,腾讯优图实验室联合华东理工大学、北京大学等研究团队,针对AI生成图像检测的泛化问题展开研究,提出了Dual Data Alignment(双重数据对齐,DDA)方法。该方法从数据层面系统抑制“偏差特征”,显著提升了检测器在跨模型、跨数据域场景下的泛化能力。
目前,相关论文《Dual Data Alignment Makes AI-Generated Image Detector Easier Generalizable》已被NeurIPS 2025接收为Spotlight(录取率仅Top 3.2%)。

发现:AI图像检测器实则在“识别训练集”
研究团队认为,问题的根源可能在于训练数据本身的构造方式。这使得检测器没有真正掌握区分图像真假的本质特征,而是“走了捷径”,依赖一些与图像真伪无关的“偏差特征”(Biased Features)来判断。
这些偏差特征是真实图像与AI生成图像在训练数据收集过程中产生的系统性差异。具体表现为:
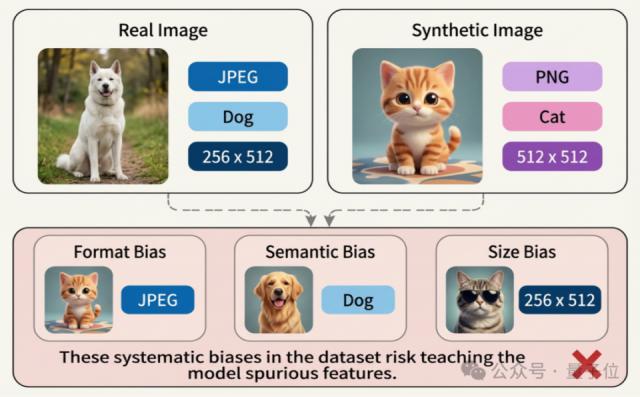
真实图像:来源渠道多样,清晰度和画质参差不齐;分辨率分布分散;几乎都以JPEG格式存储,且带有不同程度的压缩痕迹。
AI生成图像:呈现出高度统一的模式,分辨率常集中在256×256、512×512、1024×1024等固定档位;大多以PNG等无损格式存储;画面干净,无明显压缩痕迹。
在这样的数据构成下,检测模型可能会学习“投机策略”,比如认为“PNG≈假图,JPEG≈真图”。这种“捷径”在某些标准测试集(如GenImage)上甚至能达到100%的检测准确率,但一旦对AI生成的PNG图像进行简单的JPEG压缩,使其格式和压缩痕迹接近真实图像,这类检测器的性能就会断崖式下跌。
对比真实图像和AI生成图像,两者可能存在格式偏差、语义偏差和尺寸偏差:
解法与思路
针对这一问题,研究团队认为,如果训练数据本身带有系统性偏差,再复杂的模型设计也难以避免“学偏”。因此他们提出了DDA(双重数据对齐)方法,通过重构和对齐训练数据来消除偏差。其核心操作分为三步:
像素域对齐(Pixel Alignment)
利用VAE(变分自编码器)技术对每一张真实图像进行重建,得到内容一致、分辨率统一的AI生成图像。这一步消除了内容和分辨率上的偏差。
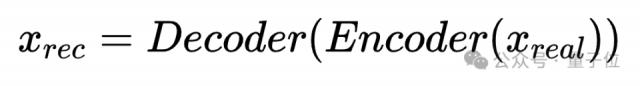
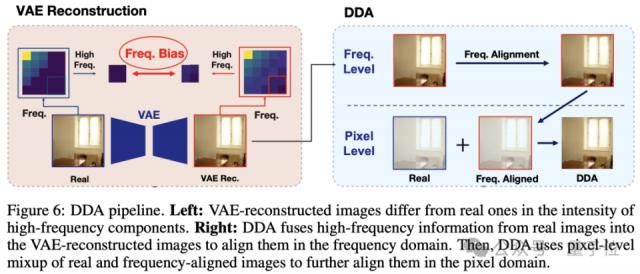
频率域对齐(Frequency Alignment)
仅像素域对齐是不够的。由于真实图像大多经过JPEG压缩,其高频信息(细节纹理)受损;而VAE在重建图像时会“补全”这些细节,创造出比真实图像更丰富的高频信息,这又形成了新的偏差。
实验也证实了这一点:当研究者将重建图像中“完美”的高频部分替换为真实图像中“受损”的高频部分后,检测器对VAE重建图的检出率大幅下降。
因此,关键的第二步是对重建图执行与真实图完全相同的JPEG压缩,使两类图像在频率域上对齐。

Mixup
最后采用Mixup将真实图像与经过对齐的生成图像在像素层面混合,进一步增强真图和假图的对齐程度。
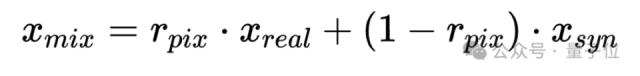
经过上述步骤,就能得到一组在像素和频率特征上高度一致的“真/假”数据集,推动模型学习更具泛化性的“区分真假”特征。
实验效果
传统学术评测常为每个Benchmark单独训练一个检测器进行评估,这种方式与真实应用场景不符。
为更真实地检验方法的泛化能力,研究团队提出了严格的评测准则:只训练一个通用模型,然后直接用它在所有未知的跨域测试集上评估。
在这一严格标准下,DDA(基于COCO数据重建)的实验效果如下:
综合表现:在包含11个不同Benchmark的全面测试中,DDA在其中10个上取得领先。
安全下限(min-ACC):对于安全产品而言,“最差表现”比平均分更关键。在衡量模型最差表现的min-ACC指标上,DDA比第二名高出27.5个百分点。
In-the-wild测试:在公认高难度的真实场景“In-the-wild”数据集Chameleon上,检测准确率达82.4%。
跨架构泛化:DDA训练的模型不仅能检测主流Diffusion模型生成的图像,其学到的本质特征还能有效泛化至GAN和自回归模型等完全不同、甚至未用到VAE的生成架构。

无偏训练数据助力泛化性提升
在AI生成图像日益逼真的当下,准确识别“真”与“假”至关重要。
但AIGC检测模型的泛化性问题,有时无需复杂的模型结构设计,而是要回归数据本身,从源头消除那些看似微小却致命的“偏见”。
“双重数据对齐”提供了新的技术思路,通过提供更“高质量”的数据,促使模型学习正确知识,专注于真正重要的特征,从而获得更强的泛化能力。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com