
AI实时语音深度伪造技术获突破,诈骗成功率近百分百





IT之家10月25日消息,用过变声器的朋友或许都知道,目前主流的语音处理方案大多存在一定延迟,而且效果越逼真,延迟往往越高。
据网络安全公司NCC Group最新披露,AI正推动语音深度伪造技术迈向“实时”阶段,攻击者能在通话中立刻模仿他人声音,诈骗成功率近乎100%。
实时语音伪造技术实现突破
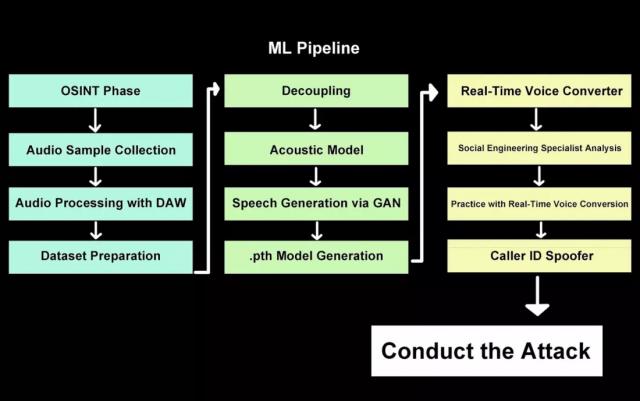
这项名为“深度伪造语音钓鱼(deepfake vishing)”的技术,借助AI模型学习目标人物的声音样本,可在定制网页界面上由操作者一键开启,实现实时语音“转译”。
研究人员表示,该系统只需中等计算性能就能运行。在一台搭载英伟达RTX A1000显卡的笔记本上,他们实现了不到0.5秒的延迟,并且没有了以往的停顿和不自然感。
测试显示,即便使用低质量录音,该系统依然能生成极为逼真的语音副本。和以往需要数分钟训练、只能生成预录音频的旧式语音伪造工具相比,这一系统能在通话中根据人的意愿实时调整语调和语速。这意味着普通人借助笔记本电脑或智能手机也能达到类似效果,进一步降低了恶意利用的门槛。
测试结果表明欺骗率极高
NCC Group安全顾问Pablo Alobera表示,在经授权的受控测试中,当实时语音伪造技术与来电号码伪造(caller ID spoofing)结合使用时,几乎每次实验都成功欺骗了测试对象。Alobera指出,这一技术突破大幅提升了语音伪造的速度与真实性,即使是普通电话通话,也可能被用于欺诈。
视频伪造发展尚未完全同步
尽管语音伪造技术已进入实时阶段,但实时视频深度伪造还未达到相同水平。近期流传的高质量案例大多依赖最前沿AI模型,如阿里WAN 2.2 Animate和谷歌的Gemini Flash 2.5 Image,将人物“移植”到逼真的视频场景中。
然而,这些系统在实时视频生成中仍存在表情不一致、情绪不匹配以及语音不同步等问题。人工智能安全公司The Circuit创始人Trevor Wiseman向《IEEE Spectrum》表示,即使是普通观众,也能从“语气与面部表情的不协调”察觉伪造痕迹。
专家呼吁建立新型身份验证机制
Wiseman提到,AI伪造技术的普及已造成实际损失。他举例说,有公司在招聘过程中被视频深度伪造欺骗,误将笔记本电脑寄往虚假地址。这类事件表明,语音或视频通话已无法作为可靠的身份验证方式。
随着AI驱动的冒充行为日益普遍,专家警告称,必须引入新的身份验证机制。Wiseman建议借鉴棒球比赛中的“暗号”概念,使用独特且结构化的信号或代码,在远程交流中确认身份。他强调,若不采取此类措施,个人与机构都将面临愈发复杂的AI社会工程攻击威胁。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com