
GPT-5:强大却无趣的新模型






千呼万唤,OpenAI 终于推出了全世界网友期待已久的 GPT-5。
不到一天时间,OpenAI 的发布推文就获得 300 万阅读、3 万点赞,世超的朋友圈和群聊也全被 GPT-5 刷屏。
尽管大家嘴上说着 OpenAI 越来越不行,不会再用,但每次他们发布新模型,AI 圈都会受到震动,不管关不关注 AI 的人都会参与讨论。可见,大家还是忘不了 ChatGPT。
那么,GPT-5 到底怎么样呢?奥特曼称这是他们做过的最智能的模型,在任何领域都达到了博士级水平。

然而,从网友反应来看,不少人对这个新版本 GPT 评价不佳,抱怨它根本不像 GPT-5,甚至不如 grok。
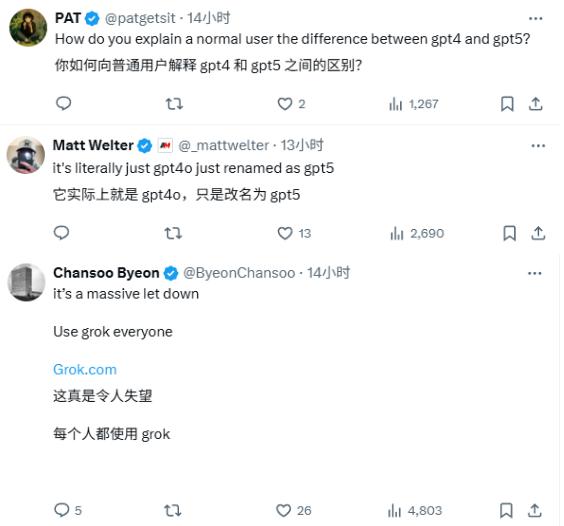
Polymarket 上发起了“哪家公司在八月末拥有最顶级的 AI 模型”的竞猜,发布会刚结束,谷歌和 OpenAI 的赔率就出现了两极反转。
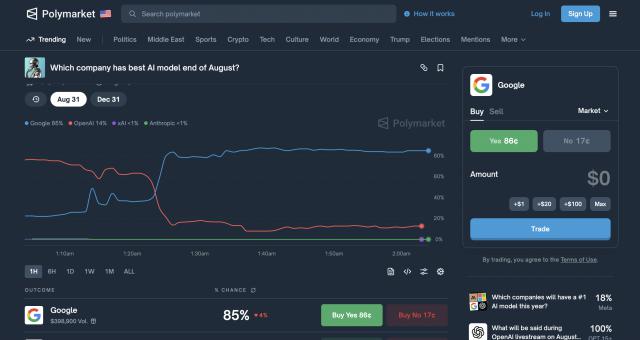
更可笑的是,发布会时 OpenAI 放的柱状图,比较大模型写代码准确度,52.8% 画得比 69.1% 还高,这失误实在低级。
网友反应大,主要是奥特曼前期宣传太夸张,还没发布就大肆宣扬。

不过,GPT-5 的跑分很强,在大模型竞技场 LMArena 上获得大满贯,全方位排名第一。
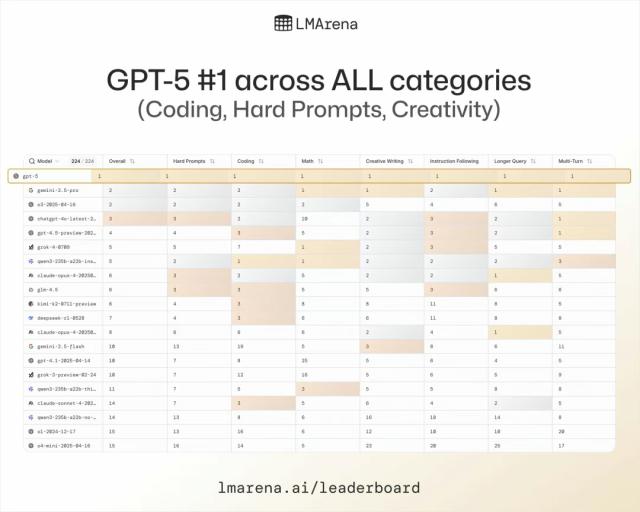
但好不好用,还得用户亲自体验。世超体验后认为,GPT-5 没那么惊艳,不如叫 GPT4.6。
首先,GPT-5 的编程能力备受称赞。拿它和竞技场榜二的 Gemini 2.5 pro 对比。
让它模拟高中的弹性碰撞,提示词为“我是一名高中生,通过物理模拟让我理解弹性碰撞”。
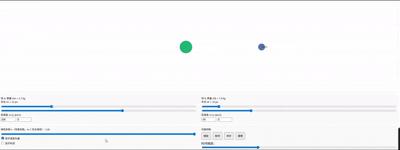
GPT-5 做得不错,能标注球的速度方向,碰撞时球的大小变化也很丝滑。而 Gemini 虽然也还行,但丝滑度不如 GPT-5,改变球大小就会卡住。
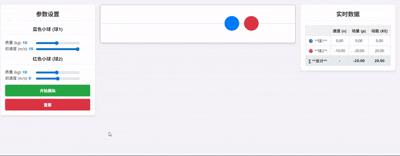
再用多米诺骨牌测试,很多 AI 都难以完成。GPT-5 做出的效果很有动感,提示词为“模拟多米诺骨牌的物理过程,左键放牌,右键倒牌”。

而 Gemini 对这个需求理解不佳,牌甚至会挂到天上。

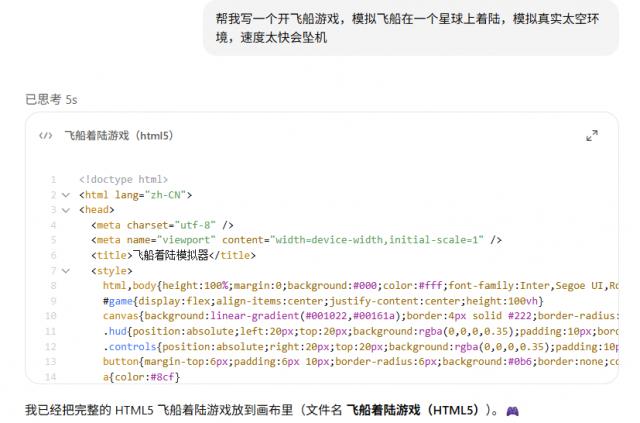
不过也有搞笑的情况,让 GPT-5 生成开飞船的游戏,结果尾焰和动力方向不一致,一出门就坠机。

除编程外,其他更新主要是对现有能力的优化。OpenAI 此次更新朝着“节能高效”方向,不同于 GPT3.5 到 4 的飞跃式更新。
据 OpenAI 官方博客介绍,GPT-5 思考和输出更高效,保证准确率的同时,思考时间更短,输出的 Token 数量减少 50% 到 80%。
它还大力解决了幻觉问题,事实错误率比 GPT-4o 低 45%,思考时的事实错误率低约 80%。
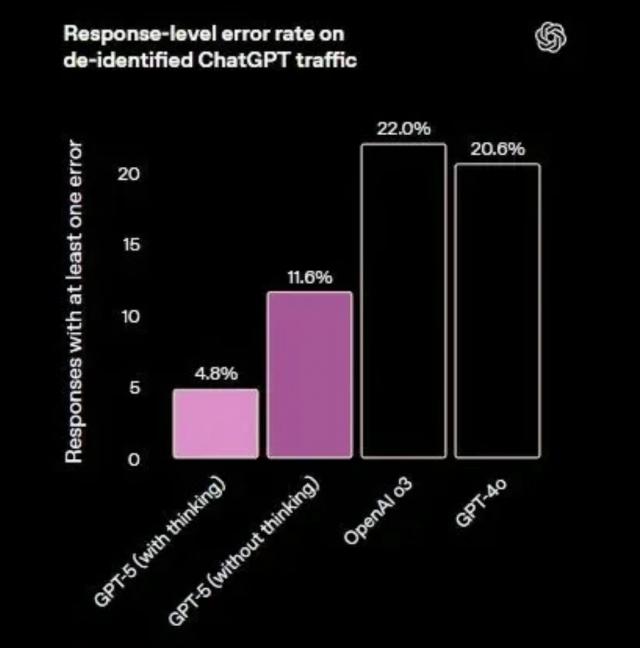
这意味着 GPT-5 更诚实,清楚自己能力边界,遇到不会的问题会直说。
对于编辑来说,模型写文章的能力很重要。但体验发现,GPT-5 在文本创作上有些力不从心,像失去灵感的诗人。
它在逻辑、推理、数学、编程等领域表现出色,但文本创作方面却有所欠缺。
让 GPT-5 撰写一段夸自己的文字,结果写了首略微肉麻的诗。

再看 Gemini 夸自己的内容,感觉 AI 味道更淡。

虽然发布会上说 GPT-5 大幅减少了幻觉,但文本变得过于保守,缺少独特视角和奇妙比喻。
此外,发布 GPT-5 时,OpenAI 强行删除了之前的其他模型,现在 GPT 界面基本只能看到 GPT-5 选项。
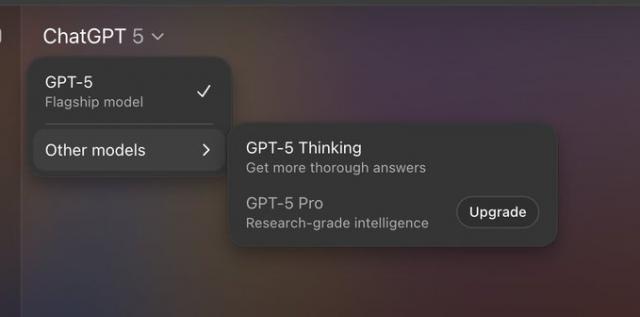
这种操作有些离谱,国内模型还能让用户选择是否“深度思考”,而 OpenAI 却收回了用户的选择权。不过,ChatGPT 的 Pro 会员还能使用旧模型。
而且,官方存在偷偷降智的行为,奥特曼发布会上展示的做音乐例子,部分用户无法复刻。
总体而言,这次 OpenAI 更新更注重“实用第一”策略。一方面可能是大模型基座性能升级遇到瓶颈,另一方面这种调整有意义,过去大模型追求性能升级忽视了幻觉、成本等问题。
如今 OpenAI 周活跃用户达 7 亿,性能升级有限时,打磨产品体验很有必要。
大家还是可以有所期待,下一个被寄予厚望的模型可能是 DeepSeek R2 和 Gemini 3.0。
撰文:不咕



本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com