
杨植麟借DeepSeek之势推动Kimi发展






月之暗面(Moonshot AI)发布开源模型K2,热闹的发布场景与过去半年的沉默形成鲜明对比。
文|邓咏仪
编辑|苏建勋
发布开源模型K2一周后,Kimi引发的全球热潮仍在持续。
7月11日,月之暗面开源了万亿参数的MoE模型Kimi K2。这是一个参数高达1T,激活参数32B的MoE模型,包含Kimi - Base和Kimi - instruct两款开源模型版本。
K2在编程、智能体类任务方面表现出色,是个“偏科”选手。Kimi公布的测评结果显示,Kimi K2在自主编程、工具调用和数学推理三个维度上,超越了同为开源模型的DeepSeek - V3和阿里Qwen3。
Hugging Face数据表明,开源一周后,K2下载量累计超10万,且还在快速增长。在大模型权威竞技场LMSYS中,K2 - Instruct已升至总榜第四,仅次于GPT - 4o、Claude - 3.5、Gemini - 1.5 - Pro。
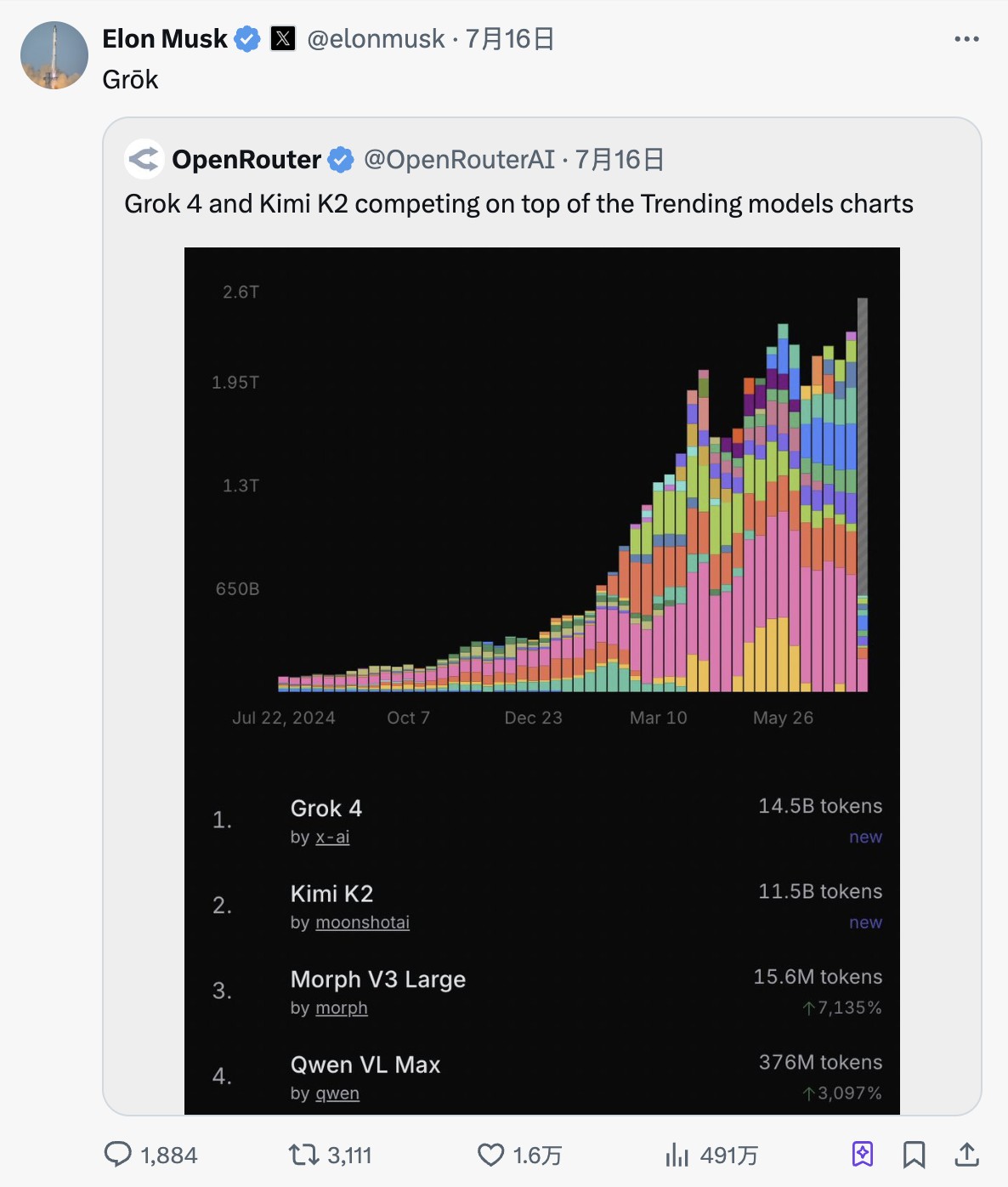
马斯克在推特转发的OpenRouter趋势数据显示,K2一周内攀升至全球趋势榜第二,仅次于Grok 4。
月之暗面此次采用全新方式开源,未进行大规模营销。
K2发布后,Kimi的算法工程师、研究员在推特、小红书、知乎等平台积极分享K2的工作和技术,回复用户疑问;Kimi官方推特也不断转发社区对K2的赞美和建议。
这种热情互动吸引了众多“自来水”。Hugging Face联合创始人Thomas Wolf对Kimi K2赞赏有加,认为开源模型正在挑战最新的闭源权重模型。
过去两年,Kimi发展起伏较大。它几乎是最后推出ChatBot助手Kimi,但凭借长文本和出圈策划一炮而红,成为最先出圈的大模型应用产品。
然而2025年,DeepSeek的出现让所有模型厂商都受到冲击。追逐AGI,证明自身技术实力,成为所有厂商的必答题。
今年Kimi转变策略,To C的Kimi应用停止投流,专注于模型研发。去年试水的Ohai、Noisee等C端应用,以及Kimi在多模态上的尝试也暂停,这引发了更多质疑。
蛰伏半年后,Kimi需要一场翻身仗,K2的发布便是回归AGI主线的宣言。
“又一个DeepSeek时刻”
K2发布引起全球开发者社区震动。7月16日,《Nature》杂志发文称K2的发布为“另一个DeepSeek时刻”。
K2重要的原因在于它复刻了DeepSeek模式:高性能、低成本且真开源,还拿出了优质成果。
K2性能强悍,专为智能体(Agentic AI)而生。
一位Kimi的算法工程师Justin Wong表示,Kimi希望将人与AI的交互方式从chat - first转变为artifact - first,即交付具体成果,而非仅提供聊天上下文。
简单来说,就是要让AI真正能干活,而非单纯聊天。
了解这一点,才能理解Kimi在模型训练路线上的选择。
DeepSeek R1发布时更注重思考、推理能力,工具调用功能在发布后很久才加入。而K2未采用推理模式,虽提升了风格化写作能力,但不过多强调。
K2最重视智能体(Agentic)能力,将提升“自主使用工具、完成任务”的能力置于首位。有从业者评价这是个罕见的选择。
具体而言,K2着重优化根据聊天上下文调用外部工具的能力,提高调用速度和任务完成质量,用户还可接入相关框架自主编程。
在K2的使用案例中,输入Prompt后,K2能迅速生成3D旋转地球模型、PPT等。

△Prompt: Create a 3D HTML mountain scene with cliffs, rivers, and day - night lighting. Supports drag/zoom, animated transitions, realistic gradients, and toggleable contour lines... (创建一个 3D HTML 山脉场景,包含悬崖、河流和昼夜光照变化。支持拖动和缩放、动画过渡、真实感渐变色,并可切换等高线显示...) 来源:Kimi
将13万行原始数据交给Kimi K2,它能分析远程办公比例对薪资的影响,生成统计图表与回归模型解读等。

△来源:Kimi
K2的另一核心优势是大幅降低模型训练和使用成本,同时保持接近Claude主流模型的性能,性价比极高。
Kimi K2 API定价为每百万输入tokens 4元,每百万输出tokens 16元,相比Claude 4 Sonnet,整体成本可下降超75%。
如今AI编程成为热门创业赛道,头部AI编程公司估值迅速增长。开发者会用脚投票,K2发布后,Hugging Face下载量激增,登上OpenRouter趋势榜周第二。
K2虽不完美,输出结果有不足,但性价比高。很多测试显示,普通程序员使用K2写一天代码成本仅需几块钱,大大降低了AI编程的算力使用门槛。
高性价比源于Kimi的原创性创新。
Kimi在训练阶段引入新优化器Muon,取代主流的AdamW优化器,在不同Llama架构模型上,Muon的算力需求仅为AdamW的52%。
优化器是大模型核心组件,决定训练时模型参数的调整。优化器越好,模型在相同硬件环境下运行更快、更稳,更节省算力。
这是一场技术冒险。Muon是前沿优化器方向,未发表正式论文,此前仅在小型模型训练中成功。但Kimi将其应用于万亿参数模型训练,并解决诸多技术难题,让Muon成为K2发布的亮点之一。
月之暗面看似朋克,实则在市场压力下,专注一个方向,用真金白银尝试新技术架构并取得成功。
这才是真正的朋克精神。
六小龙没有回头路
从K2发布能看出,DeepSeek在全球的影响仍在延续。
今年1月发布的DeepSeek R1是全球AI发展的分水岭。此前,国内大厂和AI初创公司都在争夺AI应用市场。
Kimi曾在2024年激进投流,与字节豆包竞争,但投流增长是大厂擅长的,Kimi很快力不从心。2024年11月,豆包MAU过亿,风头正盛。
然而,这些成果很快被DeepSeek R1超越。
DeepSeek之后,业界达成共识:提升模型能力才是关键。国内To C应用市场,主要剩下元宝、夸克和豆包竞争。
如今商业化并非最重要的问题,面对All in的大厂,大模型初创公司只有开源和攻克难题这一条路。
真格基金合伙人戴雨森表示,现在比拼回到技术前沿,更适合以技术大牛为核心的创业团队。
“六小龙”做出了不同选择:Kimi专注提升编程、智能体能力;Minimax和阶跃聚焦多模态;智谱走本土To B/To G路线;百川继续深耕医疗模型;01放弃超大基础模型迭代,专注大模型落地。
此前Kimi知名度有限,但K2爆火后,全球开发者开始关注它。Kimi专注提升模型能力后,其Web端数据从6月开始反弹,访问量环比增长30%。
某种程度上,开源和朋克精神相通,自由、开放、尊重技术,这是AI圈子的“注意力货币”,能建立名声、招揽人才,这是AI初创公司急需的。
一位Kimi研究员表示,2025年智能上限由模型决定,追求AGI是公司的目标。
追求AGI看似狭窄,对初创公司而言,只要专注,仍是康庄大道。
封面来源|视觉中国
??扫码加入「智涌AI交流群」??
欢迎交流
本文来自微信公众号“智能涌现”,作者:邓咏仪,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com