
Qwen,阿里大模型 3.0炸场,多次测试击败DeepSeek R1







4 月 29 阿里巴巴每天都会发布 Qwen 3 系列模型,这是 Qwen 最新的大型语言模型系列成员。此次发布的模型阵容丰富,包括:2 一位稀疏混合专家(MoE)模型:Qwen3-235B-A22B 和 Qwen3-30B-A3B1, 6 参数规模包括一个密集模型。 32B 至 0.6B,均采用 Apache 许可证。
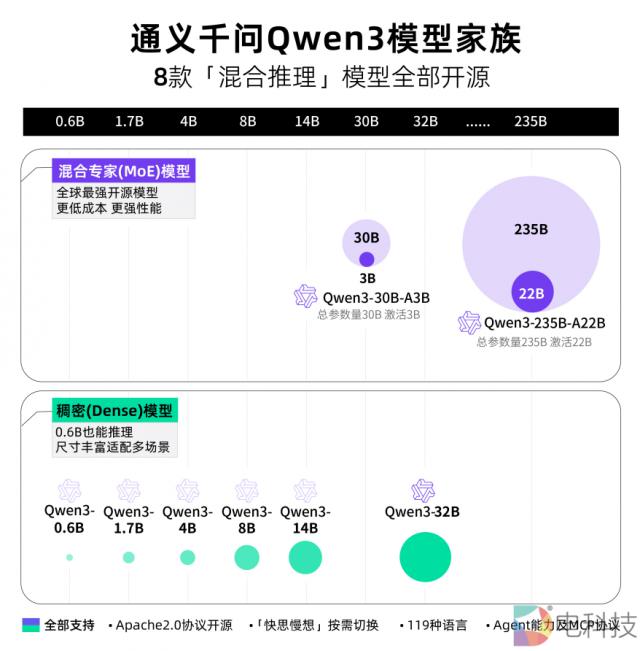
值得注意的是,Qwen3 第一次支持系列模型 119 多种语言,全球开发者、研究机构和企业都可以在魔搭社区免费使用,HuggingFace 等待平台下载模型并商业化,也可通过阿里云百炼调用。 Qwen3 的 API 服务。个人用户可以通过通义 APP 直接体验 Qwen3,夸克也将全线接入。 Qwen3。
其实在 Qwen 社交媒体在真正发布之前就已经“炸开锅”了。每个人都期待阿里这次发布一个大动作,辗转反侧。 OpenAI、国外巨头如谷歌 AI 这个领域的傲慢。这次阿里也做到了。
老板是国产开源大模型,Qwen 目前,该系列已成为世界上最热门的开源模型之一。—— 200 多个开源模型,3 亿个下载、10 一万个衍化模型,将直接 Meta 的 Llama 拉下神坛。
Meta 最小的 Llama 4 模型参数仍然达到 109B,而 Qwen 3 的 32B 在开放式模型用户中,版本非常流行。

还有“特战部队”式 DeepSeek 不同,Qwen 更像是正规军:布局早,生态强,覆盖面广。特别是对开发者特别友好,各种尺寸模型一应俱全,可以直接使用,无需费力切割。例如 Qwen 13B 这一“爆款”,如今已是 AI 应用程序开发者的首选工具之一。
反观 DeepSeek R1 虽然技术水平无可非议, 671B 参数“满血版”光硬件就要几百万,一般公司根本负担不起。这恰恰凸显了 Qwen 实用价值——不仅仅是追求参数爆炸,而是让步 AI 真实可用,好用。
在具体细扒模型之前,先看一下官方给出的新模型亮点:
“探索智能上限”再突破:通过扩大预训练和加强学习规模,实现更深层次的智能化;
国内首个“混合推理模式”:将思维模式与非思维模式无缝融合,为用户提供灵活控制思维预算的能力;
增强了 Agent 能力:从致力于训练模型的时代转变为训练模型。 Agent 时代是核心时代。
回到模型本身,这一系列模型在各种基准测试中的表现如何?
旗舰模型 A22B-Qwen3-235B- 基准测试,如代码、数学、通用能力等, DeepSeek-R1、OpenAI 的(o1、o3-mini)、马斯克的 Grok-3 和谷歌公司 Gemini-2.5-Pro 与顶级模型相比,表现出极具竞争力的结果。
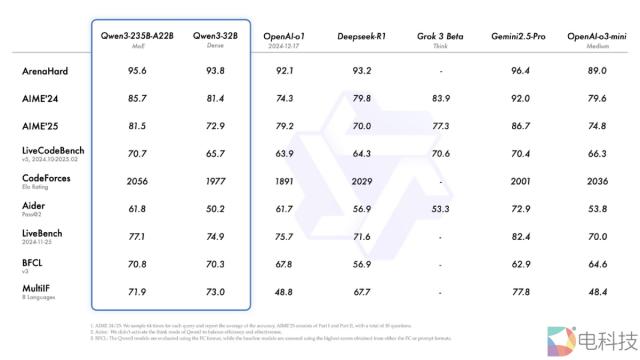
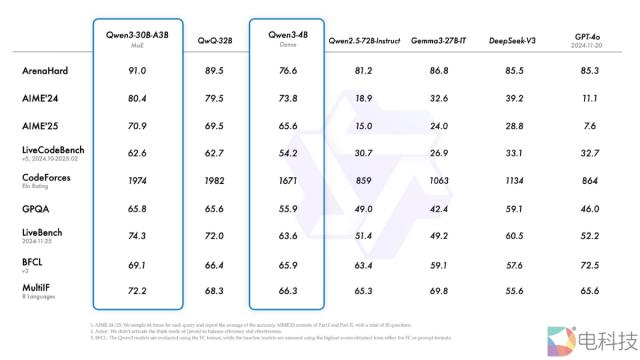
此外,小型 MoE 模型 3-30B-Qwen3-A3B 激活参数数是 QwQ-32B 的 10%,表现更胜一筹,甚至像 Qwen3-4B 这种小模型也可以与之匹敌。 Qwen2.5-72B-Instruct 的性能。
特别值得注意的是,在性能大幅提升的同时,Qwen3 部署费用也大幅下降。成本有多低?答案是 4 张 H20 可以布置满血的版本 Qwen3,显存占用率仅为性能相似模型的三分之一。
Qwen 团队中包含的基本模型评估说明,领先的基本模型 Llama 4、DeepSeek V3 以及现在的 Qwen 分数非常相似:
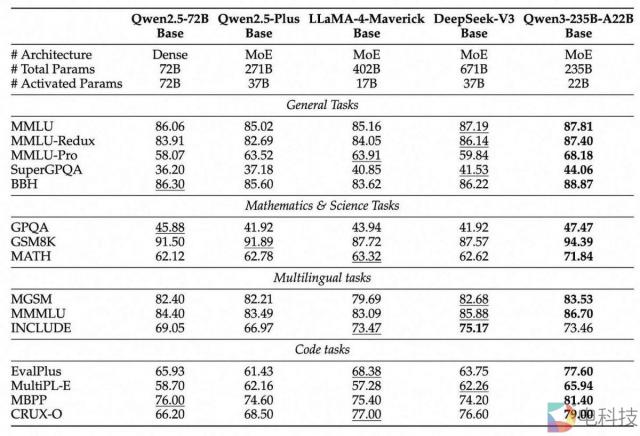
目前不同模型的关键区别主要体现在培训后的推理功能支持上,尤其是推理时间计算的优化能力上。这种改进可以从模型的评估结果中提高 40% 显着提高到 80%。
但是,目前的行业是对的 " 基础模型 " 由于这些模型在实际应用中通常需要经过大量的中期训练过程,所以它们的定义和使用仍然存在很大的混乱。在这个关键的中期训练阶段,模型会接收专门的指令数据和推理数据,本质上是为后续的正式训练后期做准备。
但事实是,没有一个主要的研究实验室公开发表了什么样的基本模型才能真正有效地支持下游训练后任务的研究成果。
这种情况让我们不得不做出合理的推断:所有这些实验室实际上都在调整自己的预训练策略,主要是为了满足自己在训练后阶段的实际需求,而不是为了优化开放社区的需求——当然,开放社区最终会从这些调整中间接受益。
可预见的是,当 Llama 4 当推理优化模型不可避免地发布时(笔者推断这一发布可能就在眼前),这些模型将立即再次成为业界关注的焦点。
这种推理模型和非推理模型之间的显著性能差距给各种模型的跟踪和评价带来了很大的挑战。但是,我相信随着更多高性能大模型的发布,这个挑战会得到改善。
Qwen3 是如何训练的?
回到模型,除了性能和参数等最重要的相关信息外,外部也会关注。 Qwen3 如何训练系列模型?
对此,Qwen 团队表示,Qwen3 全面突破了预训练数据的规模和质量。与上一代相比 Qwen2.5 的 18 万亿 token 训练数据,Qwen3 练习信息量大幅提升至约。 36 万亿 token,涵盖多种语言类型 119 种类,包括多种方言。
更新后的 Qwen3 的 token 数量几乎是以前的两倍,这么大的数据集是怎么来的?
为了构建这种超大规模的数据,团队采用了多维数据收集策略。首先是扩展信息来源:除了常规网页数据,首次系统整合。 PDF 等待文件内容,通过 Qwen2.5-VL 提取模型的文本,并使用模型 Qwen2.5 模型优化提取信息的质量。
二是提高专业领域的数据比例,针对数学和代码能力的不足,创新使用。 Qwen2.5-Math 和 Qwen2.5-Coder 生成生成数据,补充教科书级内容,结构化问答对及优质代码片段。

另外,为了平衡效率和效果,团队制定了阶段性的训练计划。
第一个阶段是基本能力塑造(S1),模型处于 30 万亿 token 数据(4K 前后长度)完成初始训练,建立基本的语言逻辑和常识思维能力;然后进入专业能力强化(S2)阶段,优先选择 5 万亿 token 高质量的数据显著提高 STEM、知识密集型内容的比例,如编程和逻辑判断;利用高质量的长前后文数据,将模型前后文的长度扩展到 32K token,使模型具有处理复杂长文本的实战能力。
得益于模型架构的不断优化,训练数据规模的加倍扩大,训练方法的效率提高,Qwen3 在综合性能上,系列稠密基础模型实现了质的飞跃。
令人惊讶的是,尽管Qwen3显著减少了参数。 然而,所有尺寸模型都表现出与上一代相当甚至更好的表现——具体来说,Qwen3-1.7B/4B/8B/14B/32B/-Base 各自达到了 Qwen2.5-3B/7B/14B/32B/72B/72B/-Base 性能水平。尤其是在 STEM 关键领域,如学科、编程能力和逻辑判断,Qwen3 密集型模型更是完成了对上一代更大规模模型的全面超越,展现了算法优化带来的显著效益。
简而言之,Qwen3 虽然身材较小,但“技巧”较大。比如 Qwen3 的 1.7B 小模型,表现已经可以赶上以前了。 3B 大型模型,而且数理编程能力更强。
更加值得注意的是 Qwen3 系列中的 MoE 通过创新的稀疏激活机制,基本模型,只需调用 10% 激活参数可以实现和实现 Qwen2.5 厚实的基础模型相当于性能表现,正如开启“省电模式”一样,通常只使用。 10% “脑力”,但效果仍然可以与老版本的全功率模型相媲美。
这一技术进步使得 AI 模型更加实用,更加经济。
预训练结束后,下一步就是模型后训练过程。
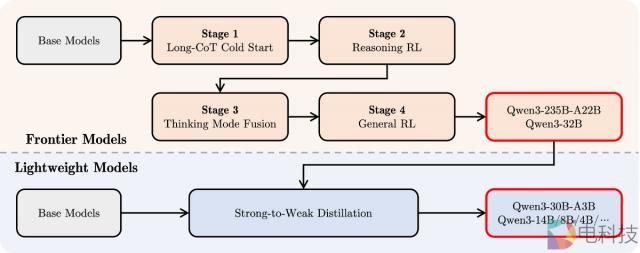
为了开发能够兼顾逐步推理和快速响应的混合模型,团队设计了一个四个阶段的后训练过程:第一阶段(长链式思维冷启动)采用多样化。 CoT 数据(包括数学,编程,逻辑判断,STEM 等待任务)微调模型,建立基本推理能力;第二阶段(基于推理的强化学习)通过扩展 RL 计算规模并采用基于规则的奖励制度,提高模型探索和应用能力;第三阶段(思维方式组合) CoT 数据与常规指令微调数据(由第二阶段增强后的模型生成)相结合,使模型融合推理和快速响应能力;第四阶段(通用强化学习)在 20 多项通用任务(如指令跟踪、格式跟踪、Agent 能力等。)进一步优化模型,增强实用性,调整不良行为。
这个过程逐渐提高了模型推理和响应能力,最终实现了快速混合表现。
现在,后训练模型(例如 3-30B-Qwen3-A3B)及其预训练模型(例如 3-30B-Qwen3-A3B-Base)都已经在 Hugging Face、ModelScope 和 Kaggle 等待平台发布。对于布署,Qwen 推荐使用团队 SGLang 和 vLLM 等框架。对当地使用,他们强烈推荐使用 Ollama、LMStudio、MLX、llama.cpp 和 KTransformers 等工具。确保用户能够轻松地选择这些选项。 Qwen3 无论是在研究、开发还是生产环境中,整合到他们的工作流程中。
另外,R&D团队还表示,他们得到了改善 Qwen3 模型代码和代理能力得到增强, MCP 的支持。
最新发布的阿里 Qwen3 在开源领域取得重大突破,不仅意味着中国 AI 模型的崛起在全球范围内树立了新的标杆。目前,阿里已经积累了开源。 200 多种模型,其千问系列衍化模型数量突破 10 万,超越规模 Meta 的 Llama 作为世界上最大的开源模型生态系列。
这一突破在多个维度上得到了体现:在技术结构方面,其专家混合模型(MoE)设计具有很大的能效优势,只要 20-30B 可以实现大规模显存成本的接近 GPT-4 推理能力;安排灵活性方面,提供 0.6B 到 32B 全系列密集型模型,支持从笔记本检测到多卡集群的无缝扩展,并保持提示词的适应;据 Venturebeat 报告显示,企业可以在几个小时内完成。 OpenAI 到 Qwen3 接口转换,大大降低转移成本。
Qwen 3 发布后的市场反应甚至突破了以前的市场反应 DeepSeek R1 发布时给行业带来的震撼。 GitHub 上次发布后,不到一天就迅速获得了。 17.9k 星和 1.2k 支部,用户口碑和行业影响力持续上升。
现在,大模型竞争已进入深水区,光能刷榜做题已不够了。Qwen 3 发布,就是对中国进行检测。 AI 一块实力的试金石。这次阿里能否继续领跑开源跑道,就看这场战斗了!
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com