
GPU又赢了?苹果在战斗中倒戈?







GPU再次获胜!2025年3月,Loop Capital曝光了一条重磅消息:Apple已经向NVIDIA购买了大约10亿美元的GB3000美元 NVL72 SuperGPU集群服务器系统 Micro Computer(SMCI)联合交付Dell。在AI领域“落后”的苹果,终于正式进入“大型服务器集群” Gen AI 游戏”。不管是技术巨头(如苹果、谷歌、Meta)或者创业公司,都是依靠NVIDIA的GPU来加速其AI战略。AI 这个领域的垄断巨头正在享受着他们的亮点。

最后苹果变成了商业GPU?
长期以来,苹果一直以自研芯片为核心竞争力,其Apple 通过深度软硬件的协同,Silicon系列在移动设备和边缘计算领域取得了巨大的成就。在此之前,苹果软件工程高级副总裁Craig Federighi曾经公开确认,Apple 自研Apple完全运行的Intelligence服务。 在Silicon服务器上,也被称为“行业云处理新规范”。
但是,这次转向NVIDIA的商业GPU,AI战略的转变,也反映了苹果对GPU生态和Gen的认可。 AI范式的优点,并且愿意因此而投入巨资。也许是生成式AI(Gen AI)自主研发芯片的开发周期和优化成本不能满足当前市场对高性能计算的迫切需求。根据Anandad分析师 据Baruah报道,苹果计划购买约250台英伟达的NVL72服务器,每台服务器的成本预计在370万至400万美元之间,总价近10亿美元。
Siri失败是导火索,业界对苹果AI一直翘首以待。不过,近几年来,Siri一直在和竞争对手(比如Google Assistant和Alexa)在对比中逐渐失去竞争力,本来预计今年春天 iOS 18.4 Siri将被更新,但是苹果已经更新了Siri。 Apple 今年三月初,苹果很少承认这一点,因为Intelligence功能推迟到明年,并且委婉地说:“我们仍然在努力创造更个性化的东西 Siri,让它更好地了解你的个人情况,并能在你的应用程序和跨应用程序中付诸行动。实现这些功能需要比我们预期的更长的时间,我们预计明年就会推出。要实现这些功能需要比我们预期的更长的时间,我们预计明年就会推出。”
两三年来,生成式AI爆红,OpenAI、Anthropic、GenGoogle等玩家 在AI跑道上飞奔,GPT-4、Claude、Gemini实现了推理、多轮对话、文档操作、编程协助等核心能力。AI 同时,PC也逐渐落地。大型模型重新定义了用户对“智能助理”的期望,客户的心理预期已经从“命令执行”向“智能协作”转变。而且作为世界上最大的手机制造商——苹果显然有点“落后”。它还促使苹果对其AI硬件战略进行重新评估,从传统的AI/ML(机器学习)转向更前沿的Gen AI技术。
这次Apple投下了这10亿美元的大单,它想干什么?有几个推断:一是建立Apple LLM,将Siri新版本嵌入,实现设备级混合部署(当地 云);建立Apple AI Cloud,远程AI增强支持iOS/macOS等设施;第三,未来将AI深度集成到iWork套件中,Health、应用程序,如Shortcuts。
尽管这次采购NVIDIA GPU,苹果不太可能完全放弃自研芯片。使用NVIDIAIA的一种可能方式 在Apple中,GPU进行模型训练和开发。 Silicon致力于推理。(inference)与边缘设备相结合。这一混合策略能在保持苹果在生态系统中控制的同时平衡性能和成本。
GPU胜利
尽管苹果在自研ASIC领域积累了很多,但是最终还是选择投入NVIDIA阵营,透露出两个关键信号:第一,优先考虑时间成为决定性因素——显然,苹果不愿意等待自研Gen。 AIASIC的长期开发进度;第二,短期内GPU的性能优势和生态成熟度,覆盖了定制化带来的效率效益。特别是NVIDIA的GPU组合CUDA生态,已经成为一个训练大语言模型(LLM)事实标准。这一“时间和性能”的选择,明确地推动了苹果的决策。
随着生成式AI(如LLM)的兴起,计算率结构提出了全新的要求:超高的并行吞吐量、大量的内存带宽和灵活的计算结构。这些需求进一步凸显了通用GPU的优势,而不是通用结构(如传统ASIC)在短时间内无法与NVIDIA的性能和生态领先水平相匹配。
过去几年,NVIDIA GPU的价格已经飙升到每粒90,000美元,其财务表现也印证了这一统治力:到1月26日第四季度,NVIDIA实现了393亿美元的收入,同比增长78%。英伟达的毛利率超过70%,远远超过竞争对手AMD的50%。这一高利润不仅反映了市场对其产品的强烈需求,也凸显了其在AI硬件领域的定价权。
从理论上讲,高昂的芯片成本可能会推高AI服务(例如ChatGPT或Microsoft) Copilot)最终将价格转嫁给客户。但是,目前硅谷科技巨头似乎更愿意自己消化这些成本,以便在AI竞争中占据先机。大约41%的NVIDIA收入来自四大客户:微软、谷歌、亚马逊和Meta,他们都表示,GPU供应不足已经成为建设AI数据中心的瓶颈。
今年 1 月份,英伟达的前景遭遇了一场震荡——中国创业公司 DeepSeek 公布了一个有竞争力的公司。 AI 模型,声称这背后的预算极其有限。一天之内,英伟达的市值几乎蒸发了 6000 亿美金。然而,在接下来的几个星期里,英伟达大部分都恢复了这些损失。行业普遍假设是,DeepSeek 这个模型暗示着更便宜的模型。 AI,只会增加全球对 AI 服务及其背后的硬件需求。科技巨头们并没有改变他们对AI基础设施的建设,而是越来越糟糕:Meta计划在今年建设AI基础设施方面花费650亿美元,包括一个数据中心,规模堪比曼哈顿的许多地区;微软、谷歌等世界九大科技公司预计2025年AI支出将达到3710亿美元,同比增长44%。
一些AI专家认为,DeepSeek的成就实际上只会巩固英伟达的地位,因为它仍然发生在英伟达的软硬件生态系统中。同时,广泛认为 DeepSeek 借助于当前的模型(例如 OpenAI 的 GPT)进行设计,这些模型的构建依赖于巨大的计算资源。
NVIDIA在硬件方面最新推出的GB300 NVL72平台堪称巅峰之作。该机架级设计集成了72个Blackwellll。 Ultra 基于Armm的GPU和36个 NeoverseGrace CPU,就像一个巨大的GPU,用于推理和训练。GB300与上一代Hopper架构相比。 响应速度为NVL72(TPS,每个客户每秒的交易数量增加10倍,能效吞吐率(每兆瓦TPS)增加5倍,AI产出能力增加50倍。这一性能飞跃使自研ASIC或传统x86 面对大规模的并行计算,CPU几乎无法与之抗衡。
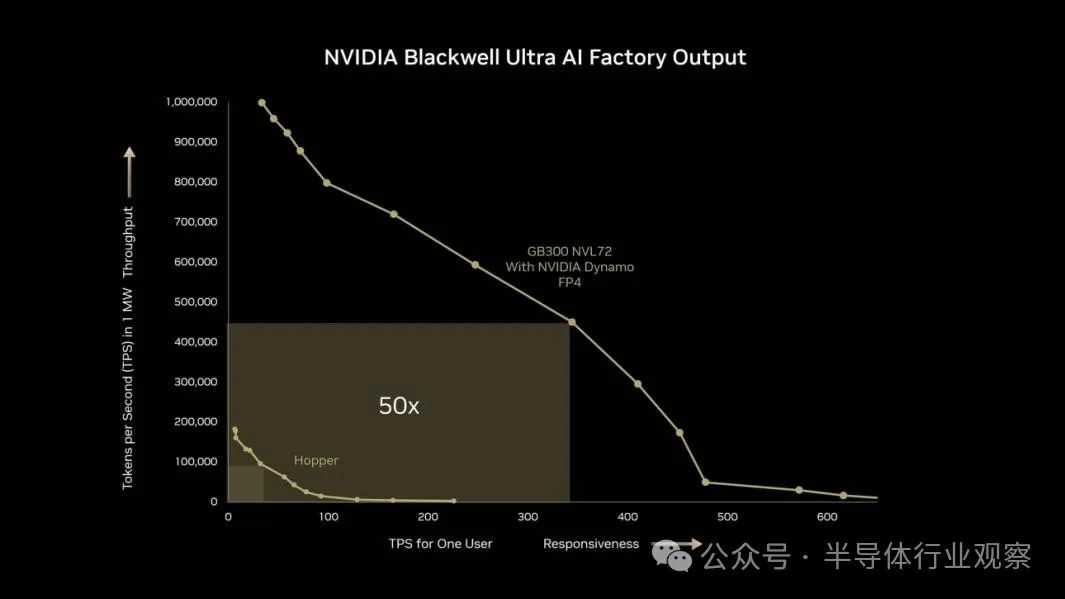
“Blackwell的需求令人震惊,NVIDIA创始人黄仁勋曾经说过。AI推理引入了一个新的缩放定律——更多的训练算率使模型更加智能,更多的推理算率使答案更加准确。"这种洞察不仅揭示了AI计算能力的两翼逻辑,也预示着NVIDIA的增长势头。展望2026财年第一季度,公司预计收入将达到430亿美元,这表明其在AI硬件市场的主导地位仍在继续。
GPU胜利不仅是技术路线的胜利,也是对时间和性能的终极追求的见证,从苹果的妥协,到科技巨头的热情投入,再到DeepSeek的意外挑战。在AI驱动的未来,GPU的通用计算率生态正成为不可动摇的基石。
“失败”ASIC
相对于GPU的耀眼成就,ASIC(专用集成电路)生成AI(Gen AI)浪潮中的暂时“失败”,为自研芯片路线敲响了警钟——在技术竞争中,“错过时间窗口”比性能稍逊更致命。
自研ASIC(如Apple)在半导体领域 Silicon)长期以来,商业GPU之间的技术路线一直存在着“定制”和“实用”的博弈。从技术特点来看,自主研发的ASIC在特定任务(如AI推理阶段)上效率更高,但其设计和验证周期长,难以跟上人工智能领域日新月异的发展节奏。相比之下,通用GPU凭借其灵活性和强大的生态支持,在AI市场的快速迭代中占有优势。
ASIC的发展进度是其最大的弱点。就拿苹果来说,作为世界ic设计的领导者,它从架构模式到流片验证还需要几年时间。然而,Gen AI的竞争是一场速度第一的赛跑,大语言模型(LLM)以月计等技术迭代周期,市场需求变幻莫测。显然,苹果很难忍受AI专用ASIC逐渐成熟的等待期。相比之下,NVIDIAGPU作为一种完善的商业解决方案,可以立即投入使用,直接满足苹果对计算能力的迫切需求。这一时间差距,成为ASIC短期内失败的关键。
ASIC的另一个缺点是灵活性不足。ASIC作为一个专门为特定任务优化而设计的“专用芯片”,在固定场景(如推理或网络加速)方面表现出色,但在Gen。 面对AI的工作负荷,却显得捉襟见肘。LLM练习涉及到多样化的算法和不断扩展的模型规模,需要硬件具有极高的实用性和适应性。而且ASIC的设计初衷正好相反,其定制特性很难快速响应AI领域的动态需求。与NVIDIA相比 GPU,在通用结构和CUDA生态学的支持下,不仅可以涵盖整个训练和推理过程,而且可以灵活地适应新算法的演变。这一灵活性使得ASIC在竞争中相形见绌。
作为ASIC设计服务的两大厂商,博通和Marvell也面临着不利局面。
去年底,The 据Information报道,苹果正与博通合作开发代号为“BaltraAI服务器芯片。该芯片专注于网络技术,预计2026年量产,仅在苹果内部使用,并采用台积电N3P技术(与OpenAI和NVIDIA的AI芯片技术一致)。尽管博通以网络加速器等定制ASIC在过去的数据中心市场表现强劲,但其产品在AI培训领域的竞争力仍然无法与GPU竞争。
通过ThunderX系列,Marvell通过Arm系列。 AI市场的CPU和定制芯片布局,但是它的方案更倾向于推理而不是训练,不能满足苹果对大规模LLM训练的需求。
此前苹果透露,它还在探索使用亚马逊的Trainium2芯片。 AI 模型预训练。现在选择英伟达GPU,还是证明了通用GPU,尤其是英伟达GPU的短期地位难以撼动。
当然,这并不意味着ASIC已经完全退出了舞台。未来苹果可能会采用“GPU训练” 利用NVIDIA完成模型开发的ASIC推理混合策略,然后使用Apple。 Silicon改进了边缘部署。但是,在现阶段,ASIC的“失败”更多的是时间窗口的失败,而不是技术的结束。
总结
购买NVIDIA的苹果10亿美元 GB300 NVL72的决策,不仅是AI战略的急转弯,也是GPU在生成式AI时代统治力的又一注脚。在这场技术和时间的比赛中,由于其现成性和适应性,通用计算率克服了定制策略的长期潜力。即使是自主研发能力如苹果的巨头,也不得不向现实低头。失败的Siri,Gen AI的狂飙,以及用户对“智能协作”的新期待,共同将苹果推向英伟达的怀抱。但是,这并不是ASIC的终曲,而是时间窗口和生态游戏的阶段性结果。在未来,当苹果的自研芯片和GPU的混合战略完善时,AI算力之争可能会迎来一个新的转折点。但至少目前,英伟达的GPU不仅是技术胜利,也是时间铁律的化身——在AI的狂潮中,谁能更快站在风口浪尖上,谁就抓住了定义未来的钥匙。
本文来自微信公众号“半导体行业观察”(ID:icbank),作者:杜芹DQ,36氪经授权发布。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com