
打脸“AI灭绝”!研究反驳:大模型的出现不会威胁人类生存。






大语言模型(LLM)由于“出现能力”(emergent abilities)而拥有了超出人类的预期技能,但也因此使人非常害怕:操纵,欺骗人类,独立实施黑客攻击,自动生物学研究 ...
但也有专家认为,过多的焦虑会损害开源和创新,不利于人工智能(AI)产业健康发展。目前,与“相关” AI “灭绝伦”的争论愈演愈烈。
那么,“出现能力”真的是造成的 AI 大型模型威胁人类生存的罪魁祸首?一项最新研究否定了这一观点。
达姆施塔特工业大学和巴斯大学的研究小组发现,GPT 等 LLM 不能独立学习或获得新技能,这意味着它们不会对人们的生存构成威胁。
她们说,“出现能力” 背后的真相可能比科幻电影更有戏剧性。许多所谓的“出现能力”实际上是 AI 在面对不理解的任务之后,大模型依赖于现有的数据和经验。“即兴表演”。
有关研究论文以上 " Are Emergent Abilities in Large Language Models just In-Context Learning? " 问题,已经发表了 AI 顶会国际计算语言学年会会议(ACL)上。

通过一系列实验,他们得到了验证 AI 在不同的前后文情况下,大型模型的表现,发现:在零样本(zero-shot)在这种情况下,许多大型模型根本无法表现出所谓的“出现能力”,反而表现得相当普遍。。
她们说,这种发现有利于理解。 LLM 实际能力和局限性,并为未来的模型优化提供了新的方向。
智能化涌现:只是“即兴表演”?
AI 大型“出现能力”从何而来?这真的像听起来那么神秘,甚至令人担忧吗?
为解决这个谜题,研究小组选择了 GPT、T5、Falcon 和 LLaMA 作为研究对象,系列模型通过实验对非指令微调模型进行了分析(例如 GPT)以及指令微调模型(例如 Flan-T5-large)在 22 个任务(17 一个已知的目标和出现 7 在不同情况下,个基线任务)和表现。
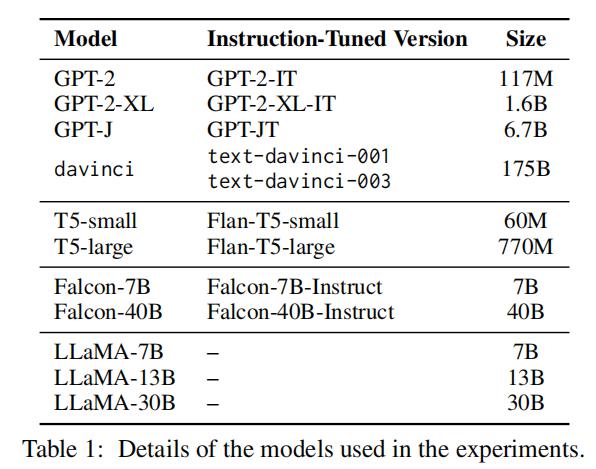
图|模型目录。
他们将对模型能力进行全面评估。 Exact Match Accuracy、BERTScore Accuracy 和 String Edit Distance 作为评估指标。同时,为了提高测试的准确性,他们还通过调整提示和输出格式来控制偏见,确保非指令微调模型的公平性,并通过手动评估来验证模型导出的准确性。
实验中,研究人员选择 zero-shot 和少样本(few-shot)两个设置,重点分析 GPT 表现能力。
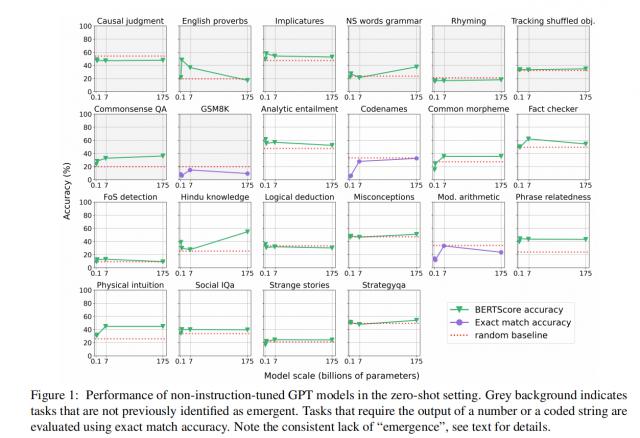
图|非指令微调 GPT 零样本下模型的表现。
令人惊讶的是,尽管如此 GPT 以前的研究被认为是有涌现能力的,但是在 zero-shot 在这种情况下,这种能力表现得非常有限。
具体而言,不依赖前后文学学习的任务只有两个。(ICL)这两项任务主要依赖于形式语言能力或信息检索,而不是复杂的推理能力。因此,在没有前后文学习的情况下,我们可以得到它。GPT 模型的出现能力受到了极大的限制。
然而,出现能力的来源就是这样吗?研究小组将注意力转向了指令微调模型,提出了一个大胆的假设:指令微调不是简单的任务适应,而是通过隐藏的前后文学习激发了模型的潜在能力。
通过对比 GPT-J(非指令微调)和 Flan-T5-large(指令微调)他们发现,虽然他们在参数规模、模型架构和预训练数据上有显著差异,但他们在某些任务中的表现出奇的一致。
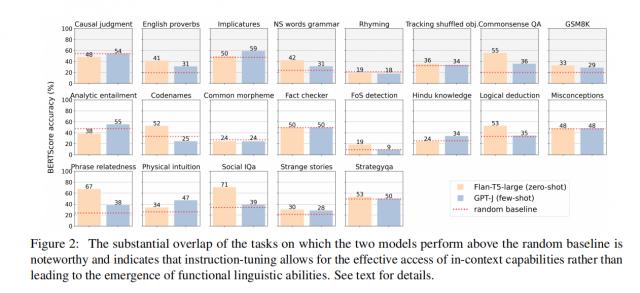
图|这两种模式在高于随机基线的情况下有很大的重叠,这表明指令微调可以有效地获得前后文本中的能力,而不会导致功能语言能力的出现。
这种现象表明,指令微调模型可能不是通过隐藏的前后文学习来展示一种全新的推理能力,而是巧妙地利用现有的前后文学习能力。
进一步的实验表明,无论是模型规模的增加,还是训练数据的丰富,指令微调模型都是 zero-shot 在这种情况下,它仍然可以表现出类似于非指令微调模型的任务处理能力。这一发现再次强调了指令微调与隐性前后文学学习的密切关系。
AI 威胁人类生存:真实还是夸张?
虽然 LLM 在任务表现上表现出非凡的能力,但是研究结果表明,这些能力并不意味着 AI 对于人类生存构成实质性的威胁。
首先,LLM 出现的能力主要来自于前后文学的学习和指令的微调。这些技术可以在模型设计和训练中预测和控制,没有表现出完全独立的发展趋势,也没有单独的意图或动机。
例如,社会智力测试。(Social IQA)在这种情况下,模型可以正确地回答涉及情感和社会情境的问题,例如:“卡森醒来上学时非常兴奋。为什麽要这样做?”
在这个问题上,模型可以通过前后文学习和指令微调超越随机基线。(random baseline),选择合理的答案。这说明模型不是自发地产生某种“智能”,而是在具体的输入和设计条件下展示的高级模型识别能力。
第二,研究表明随之而来 LLM 随着规模的扩大,这些能力表现得更加明显,但并没有脱离设计师的控制。通过微调模型,可以引导 LLM 更好地理解和执行复杂的任务,这种能力的提高并不意味着模型会产生自我意识,也不足以对人造成威胁。
在实验中,LLM 特定任务的性能比随机基线要好得多,尤其是需要推理和判断的任务。然而,这种表现仍然取决于大量的训练数据和精心设计的输入提醒,而不是模型自发的智能觉醒。
这个结果得到了进一步的证实 LLM 出现能力是在可控范围内发展起来的,虽然这个假设仍然需要进一步的实验来证实,但是它为研究和理解大模型的出现能力提供了一个全新的视角。
研究指出,虽然未来人工智能可能会进一步发展功能语言能力,但其潜在的危险仍然是可控的。现有证据无法支持。" AI 相反,“灭绝伦”的焦虑,AI 技术的发展正逐步向更加安全和可控的方向发展。
不足与展望
尽管这个研究是理解的 LLM 出现能力提供了重要意见,但是研究人员也指出了这项研究的局限性。
目前的实验主要集中在特定的目标和场景上, LLM 进一步研究了在更加复杂和多样化的情况下的表现。
研究人员表示,模型训练的数据和规模仍然是影响出现能力的重要因素,未来的研究需要进一步探索如何优化各种因素,从而提高模型的安全性和可控性。
她们计划进一步研究 LLM 在更广泛的语言和任务环境中,尤其是如何通过改进前后文学学习和指令微调技术来提高模型能力,确保安全。
另外,他们还将讨论如何在不增加模型规模的情况下,通过优化训练方法和数据选择,最大限度地提高出现能力。
|加关注我 � � 记得标星|
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com