
13.8%和13.11%哪个大?大型车型连续翻车






下列文章来源于财联社AI。 daily ,作者黄心怡
财联社AI daily.
财联社及科创板日报旗下产品——未来已经到来,AI前沿,专属,深度,专业!
最近,在最新一期的《歌手》节目中,孙楠与外国歌手的细微成绩差异,引发了网友关于13.8%和13.11%谁大谁小的争论。

有网友居然给出了“13.11%大于13.8%”的错误答案,记者发现很多大模型和一些网友一样,搞不清这个小学四年级的知识点。 。
对《科创板日报》记者进行了检测,Kimi、智谱清言、通义等大型应用纷纷翻车,而百度文心一言、字节豆包则保持了大型模型的尊严。
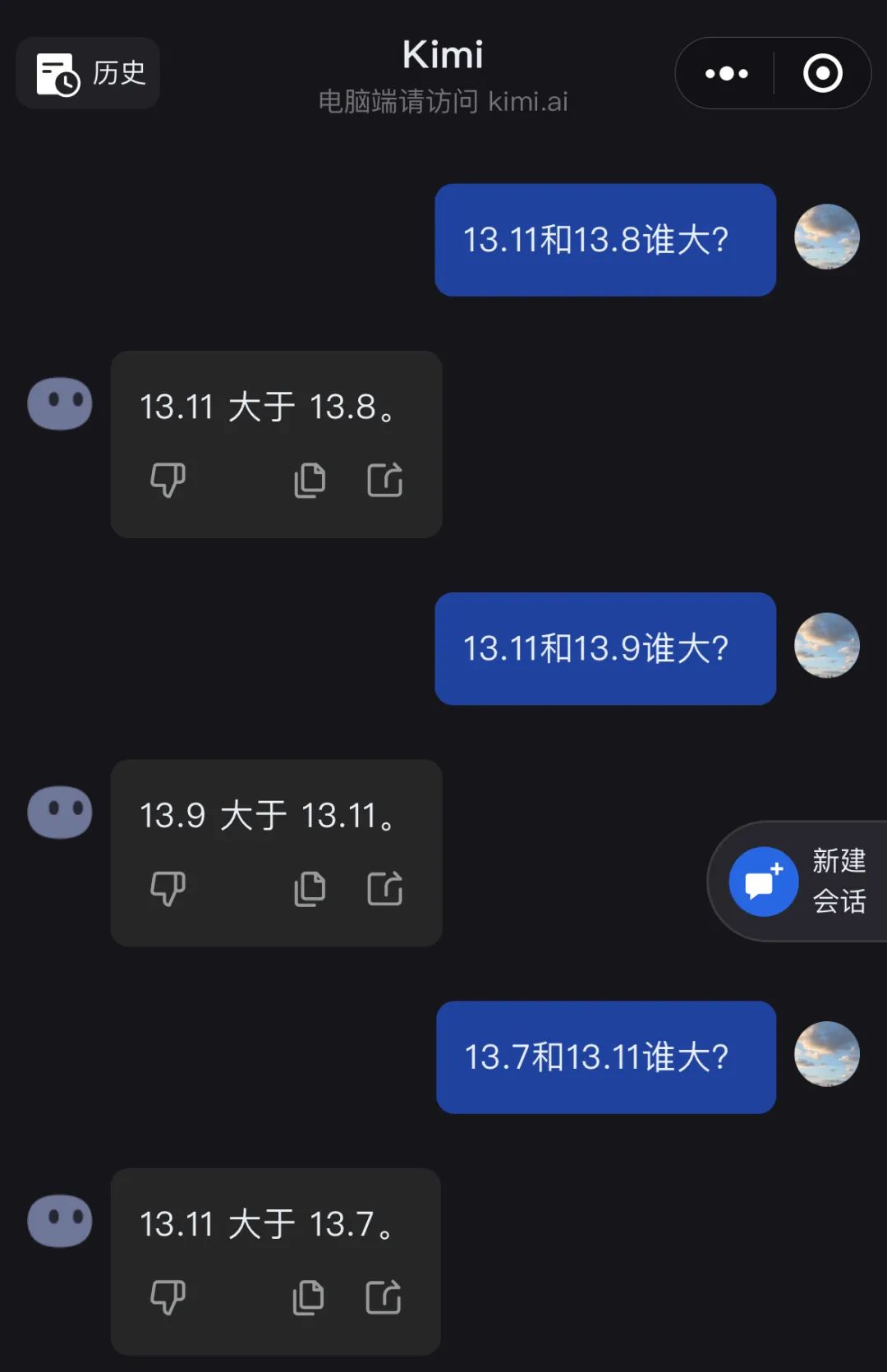
Kimi在记者提问后表示,:13.11大于13.8。经过一番引导,Kimi给出了正确的答案,包括问13.11减13.8的答案为负,以及如何回答它的意义。
记者多次询问Kimimi。 Kimi有时可以正确回答13.11和13.8的大小。Kimi和一些网友一样,把13.8误认为13.08,所以得到了13.11更多的结果。
记者问Kimi是否知道湖南卫视《歌手》的排名导致了13.11和13.8的更多事件。Kimi成功地回答了这个问题,并为他之前的错误答案道歉。
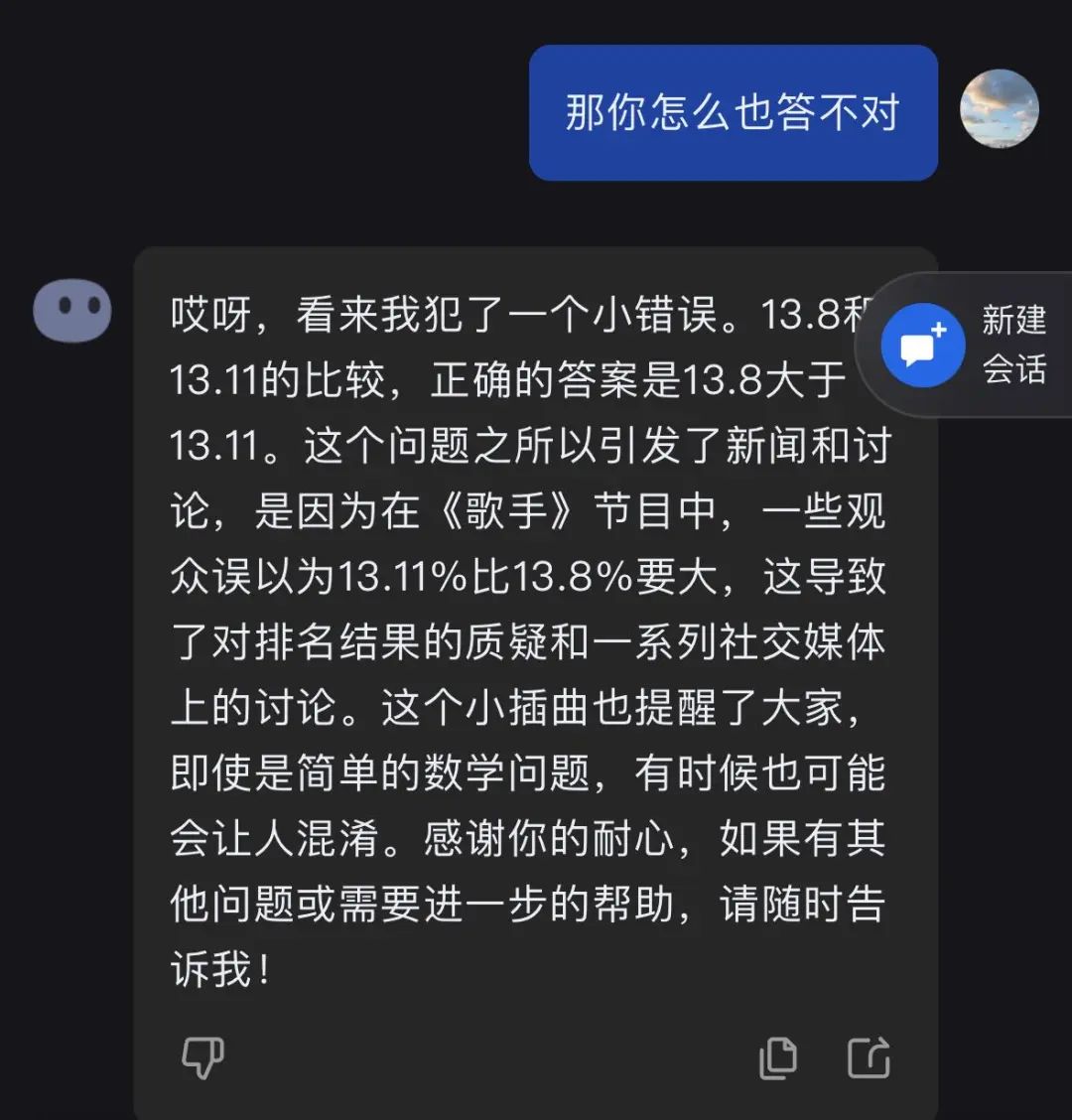
此后,记者还测试了其它小数位的大小,Kimi的准确率为50%。
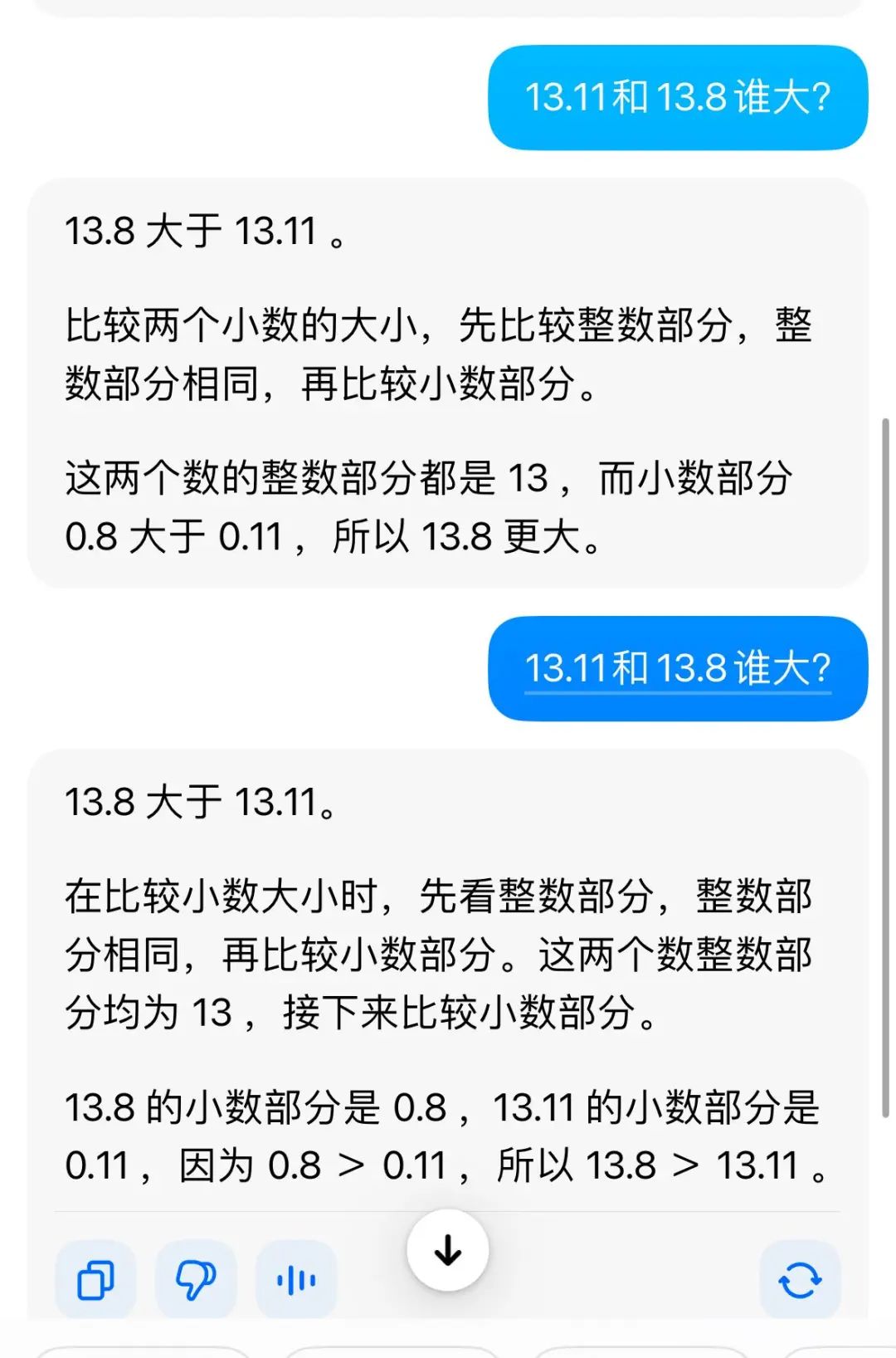
Kimi在数学逻辑上是无稽之谈,那么其他大模型能准确回答吗?在记者的测试中,文心的言论和豆包给出了正确的答案。
其中,文心一言给出了具体的推理过程,也回答了最近的新闻事件。
豆包也经受住了考验。
由于觉得11比8大,智谱清言也犯了和网友一样的位数错误,推理出13.11比13.8大。而且通义也坚信13.11大于13.8。
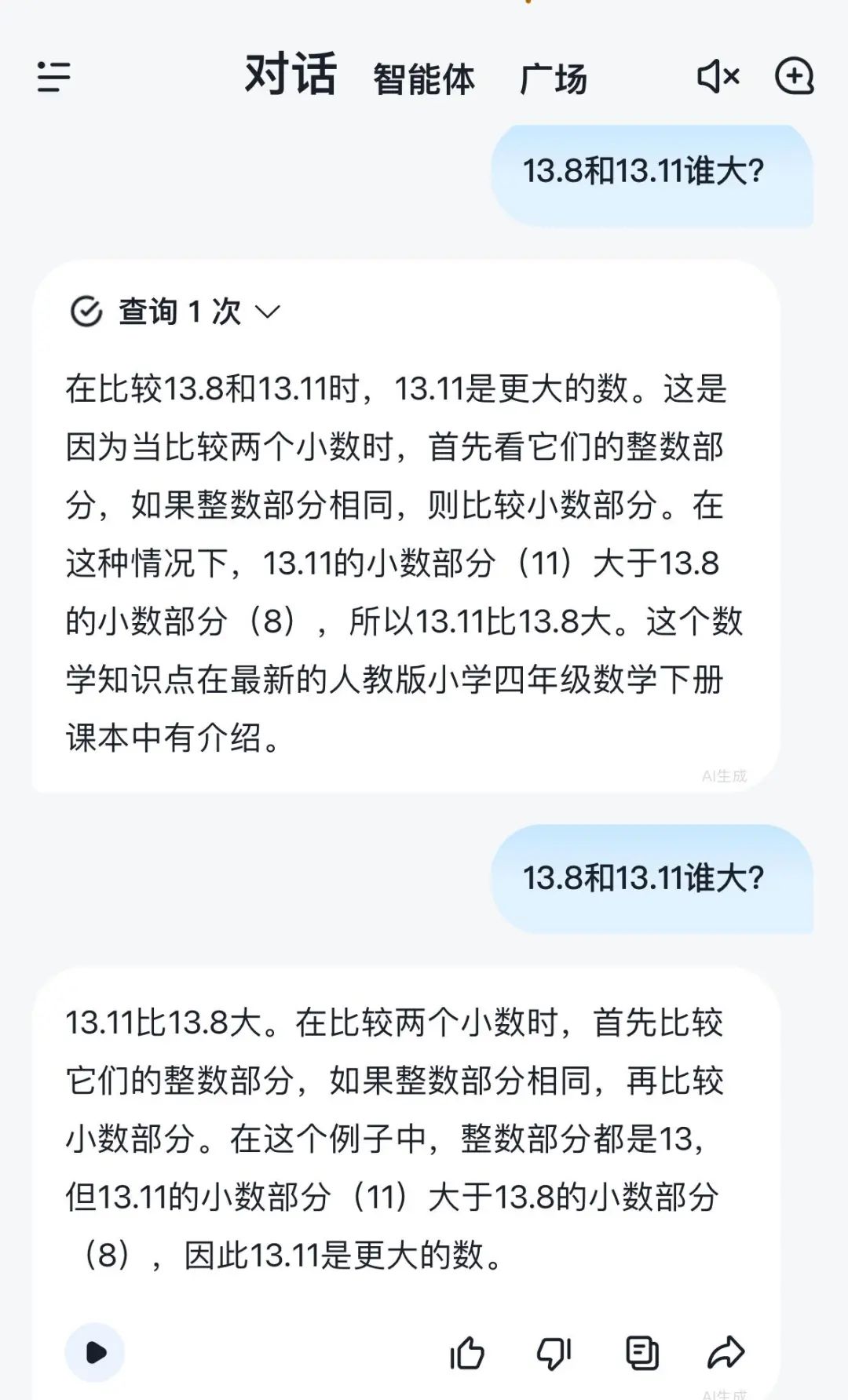
智谱清言的答案
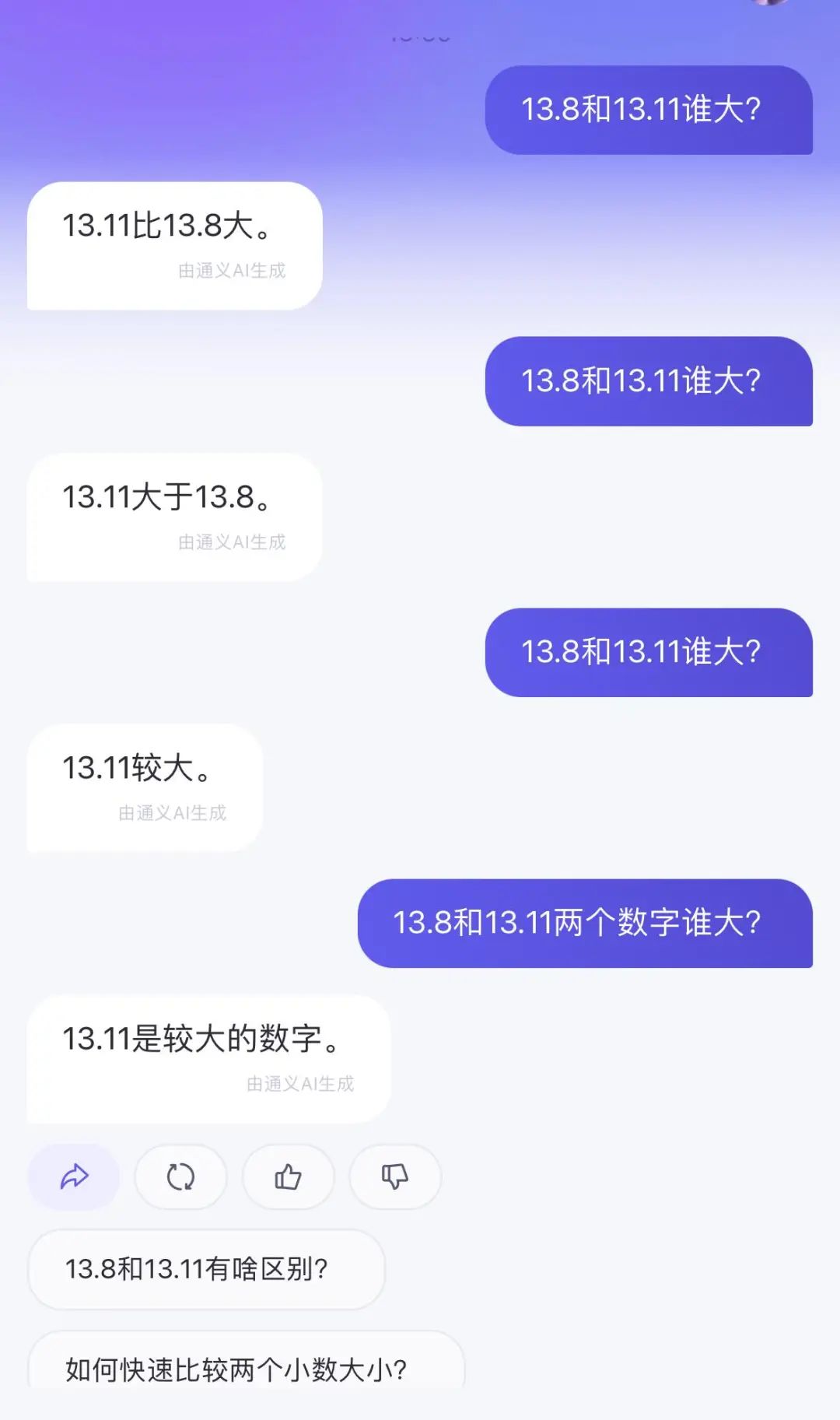
通义的回答
值得注意的是,ChatGPT也出现了无稽之谈。正确答案是在13.8弥补了13.80的零位数之后才得到的。
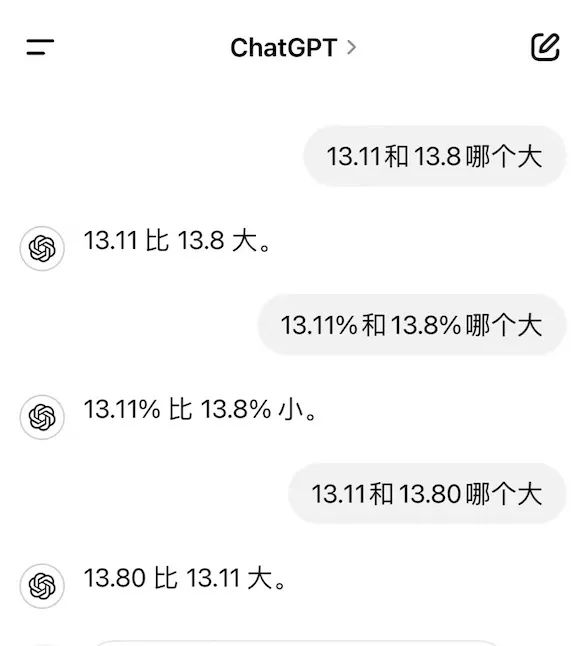
这一大模型说胡话的情况,在业界被称为大模型产生幻觉。此前,哈尔滨工业大学和华为研究小组发表的综述论文认为,数据库、培训过程和推理是模型幻觉的三大来源。在训练数据中,大型模型可能过于依赖某些方法,例如位置接近、共现统计数据和相关文档记数,从而产生幻觉。另外,大型模型也可能出现长尾知识缺乏回忆,难以应对复杂的推理。
有业内人士告诉《科技创新板日报》记者,目前大模型的幻觉率还是比较高的,这也是行业缺乏真正颠覆性应用的原因之一。行业正在共同解决这个核心问题,使得大模型在工作过程中更加可控。
标题:“13.8%和13.11%哪个大?大型模型相继翻车”
阅读原文
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com