
英特尔LunarLake架构分析:单核暴增,Xe2首秀








2024 年 6 月初,英特尔方面 COMPUTEX 展览期间,传闻已经正式公布了很久。 LunarLake 详细的平台信息。
作为英特尔下一代低功耗笔记本电脑计算平台,LunarLake 毫无疑问,定位就是接任现在。 MeteorLake。但是就其具体设计而言,LunarLake 而且并不是单纯的基于这一代人的规格增强,因为它的变化实在是太大了,甚至可以说是有点“颠覆”。
那么,这一代英特尔移动平台是如何设计的,会对产品形态和技术路线产生怎样的影响呢?接下来,我们来看看刚刚公布的。 LunarLake 建筑相关信息吧。
变化综述:4 4CPU、集成内存、NPU 性能暴增
第一,我们简单介绍一下 LunarLake 几个主要特征。
在 CPU 方面,LunarLake 使用了最高 4P 4E 设计。必须说,这实际上是相当令人惊讶的,因为上一代的原因 MeteorLake 最多但拥有 6P 8E 2LPE 的 16 核 CPU,所以如何利用一半的核心数量来提高英特尔的性能,显然是这次的重点。
在 GPU 方面,LunarLake 正如我们之前猜测的那样,全新的一体化。 Xe2 结构核显。除了更多 GPU 除了规格之外,一个非常明显的变化就是重新加入了之前的“核显版” ARC 上被删除的 XMX 矩阵计算模块。
与此同时,LunarLake 它还成为英特尔历史上第二个集成内存。 CPU 设计。之所以说是第二款,是因为在之前。 13 在代酷睿平台上,已有 i9-13905H 这个方案包含了试验特性,选择了“超短内存走线”的设计。在那个时候,它已经证明内存是直接集成的。 CPU 在基板上,比常规内存或主板焊接内存更容易更频繁地更换(因为线路更短,影响更小,有利于使用更高频率的颗粒)。LunarLake 很明显,就是这一设计理念的“推广”应用。
最终,LunarLake 的内置 NPU 规格也是前代的 10TOPs,一跃升至最高水平。 48TOPs。还有它的 GPU 现在也有高达 67TOPs 的 AI 性能,加上 5TOPs 算力的 CPU,总而言之,就可以达到 120TOPs 的"平台 AI 算率"。
很显然,LunarLake 显然是一款迎合当下的“ AI PC “时尚的处理器设计。但是与 AI 特征,其它部分也许更值得关注。
"超宽型" CPU 设计,小核已经达到了过去大核的性能。
LunarLake “凭什么”勇于使用 4 4 核的 CPU 设计?其中一个很大的原因, CPU 结构发生了很大的变化。特别是这些 E 与上一代相比,核(能效核、小核)的性能有所提高。 2-4 倍之多。所以即使只有 4 核心,实际表现不一定已输给上一代。 8E 配备了。同时,它的 P 这次核的变化也不小。
首先是 E 核。LunarLake 这次采用了全新的 E 核心设计,取消上一代 MeteorLake 这里位于低功耗岛内部。 LPE(超低功耗能效)核心,所以相当于“回归” 12 代表酷睿开始" P E "混合结构。它也意味着 LunarLake 的 E 这一次,核心不仅要用更少的核心数量达到足够高的峰值性能,还要在低频运行时达到极低的功耗,以取代以前。 LPE 核心功能。
那么它是怎么做到的呢?简而言之,这源于新一代。" Skymont “结构”。而且它的变化实际上可以用一个词来形容,那就是“宽”。
与上代的 E 核相比,Skymont 该结构的解码模块使用 3*3 的 9 总宽度设计,比上一代增强了整体性。 50%。
与此同时,其乱序执行引擎也大幅扩大。它的总分配宽从 6 发射改成了 8 发射,指令退伍模块从 8 总宽倍增到 16 重定序缓冲,总宽度,乱序执行窗口(ROB)容量从 256 大幅增至 416 个指令。此外,更深层次的指令队列长度,更多的载入和储存缓冲区域,以及多达 26 一个预取接口,全部使用 Skymont 在各种意义上,架构的关键规模已经超过了类似名称的经典架构。 Skylake。
还有一个非常有趣的悬念,那就是 Skymont 这次内置了四组结构 128bit 的浮点和 SIMD 矢量模块。嗯,四组 128bit,想必大家都知道,看来大家都知道, AVX512、或者更加准确地说 AVX10.1 指令集来到消费等级 E 核日,或许不远了。
根据英特尔方面发布的相关数据,Skymont 架构 E 目前的单核整数 IPC 相当于上代 LPE 节能核 138% 水平,浮点性能是 168%。
在计算了频率增长带来的性能提升之后,全新的 E 现在每个核心都可以顶过去了。 2 一个低功耗核的水平,甚至在低功耗范围内胜过 13 代酷睿的 Raptor Cove 大核。也就是说,LunarLake 如今的每一个能效核,都有比过去“性能核”更高的同频性能,同时也可以兼顾“ LPE “超低功耗等级功能。而且这个,就是它有勇气只设计四个。 E 核心的自信。
更大更强的性能核,在架构模式上有悬念。
讲完了 LunarLake 能效核,下面我们来谈谈它的性能核,也就是常说的。 P 核、大核。

和能效核一样,英特尔这次也完全重新设计了新处理器的性能核结构,现在它被称为“” Lion Cove "新的结构。
与 Skymont 同样,更宽更多的并发处理能力也是一样的。 Lion Cove 改进结构的主要思路。比如它的前部会增加预测区块 8 倍之多,预取模块更宽,同时还增加了微操作的缓冲容量。
但是在执行单位部分,Lion Cove 将分配 / 重命名模块的宽度来自 6 增加到 8 个人,指令退伍模块的宽度从 8 个增加到 12 一个,指令窗口深层从 512 增加到 同时执行接口也从576开始。 12 个增加到 18 个。
与此同时,Lion Cove 目前,该结构具有更大规模的整数执行设计,其算术逻辑单元从 5 个增加到 6 个,64*64 乘法模块从 1 个增加到 3 个。
但是在浮点部分,Lion Cove 的 256bit SIMD 模块也从 3 个增加到了 4 个体,浮点除法器的数量翻了一番,同时也减少了乘加计算的指令延迟。另外值得注意的是,每个人都知道隔壁。 AMD 是用2个 256bit SIMD 实现模块 AVX512 适应指令集,而英特尔这次将会 Lion Cove 内部的 256bit SIMD 模块数量增加为 4 组,也算是再一次暗示了未来 512bit 消费级别集中向量指令 CPU 上回归的可能性。
也许是为了更好地应对更宽、吞吐更多的架构模式,英特尔也首次在 Lion Cove 在结构中引入了大容量的结构。 L0 缓存。事实上,他们说他们增加了新的“ L1.5 “缓存可能更准确。因为从本质上讲,现代 CPU 事实上,它们都含有很小的内容 L0(通常只有几个 KB、甚至不到 1KB)用于存储微操作指令。而从 Lion Cove 与上代 Redwood Cove(注:MeteorLake 在性能核的对比中不难发现,新的缓存实际上相当于在 L1 和 L2 在中间增加了一层新的缓冲层,以减少较大的缓冲层,但循环周期较长。 L2 影响延迟。
根据官方公布的数据,Lion Cove 性能核结构 IPC 大概比上一代有所提升 14%,而且特别是在低频部分,优势会更明显,更接近, 20%。
放弃超线程,但是多线程能效反而暴增。
除架构模式较宽外,LunarLake 的 CPU 这次还有一个很大的变化,那就是取消性能核的超线程功能。
需要注意的是,根据英特尔的说法,取消超线程并不一定是因为架构硬件不支持,主要是因为平台能效比的决定。因为他们发现,对于今天的“性能核”来说,增加超线程功能可以提供一个大概的想法。 30% 多线程增益,但同时会消耗更多 20% 的功耗。
但是由于 LunarLake 能效核的性能比以前强多了,导致性能核的超线程模块相比之下非常“不划算”。由于新处理器的能效核和性能核之间的差距没有以前那么大了,他们的方法是直接使用能效核来承担更多的多线程计算。
与此同时,LunarLake Cpu现在具有大幅优化的“线程调度器”和电池管理特性。它的小核现在有一个独立的电池管理模块,大核的主频调整步骤不再是过去。 100MHz、但细化为可以遵循的 16.67MHz 自动调整一步一步、频率。
因此,一方面操作系统(目前主要是 Windows 11 最新版本)可以更清楚地“知道”哪种类型的程序应该在什么类型的关键上运行,从而避免过去的性能核动总是被低功耗程序激活和浪费功耗。
另一方面,当笔记本电脑处于功耗有限的情况(如电池模式或低噪音排热模式)时,新的处理器可以根据实时性能要求尽可能细致地调整主频,从而解决了低功耗模式下主频率过低、性能不足的问题。
核显补短板,内存设计避免“简配”
最后,我们来谈谈吧 LunarLake 这一代的核显部分设计。
事实上,LunarLake 核显将被加回 XMX 我们三易生活很久以前就猜到了这个模块。因为它是现代的。 Intel ARC 独显而言,XMX 这个模块不仅重要 AI 对游戏中的资源进行计算, AI 超分、AI HDR 等待最新的场景增强功能,也会有很大的帮助。

但在实际结构上,LunarLake 这次集成化 Xe2 GPU 结构也不是简单的“加回” XMX 模块。此外,它还大大提高了内部渲染切片的吞吐率,将线条预取和网格遮盖性能提高到原来的水平。 3 倍。
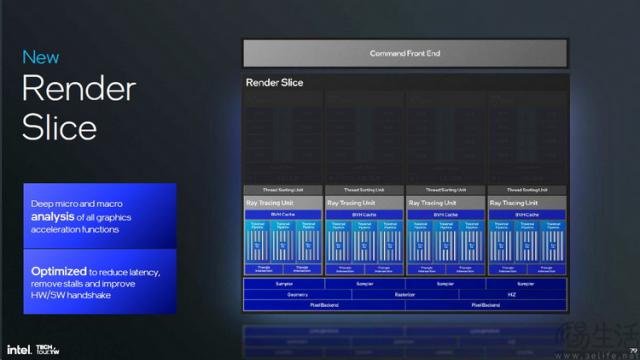
同时,新的 GPU 核心还采用了“更大更宽”的改进思路。它的采样吞吐量和渲染吞吐量都翻了一番,像素色缓冲增加了。 33%。与此同时,英特尔也全面重新设计 Xe2 光追引擎,大大提高了光追的计算效率,减少了打开光追后帧率的损失。
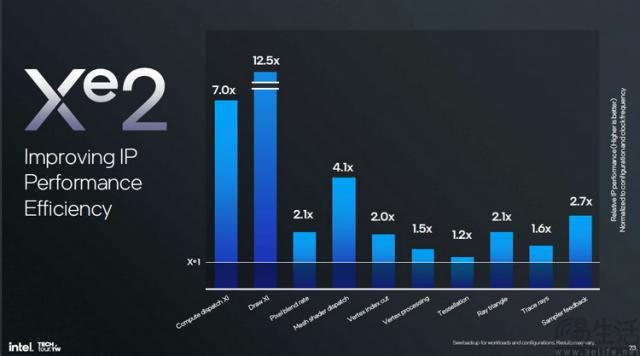
据官方公布的数据显示,与上一代相比 Xe 架构的 ARC 核显相比,LunarLake 的 Xe2 单时钟周期内架构的光追性能已达到上一代。 1.6 两倍,取样反馈性能为上一代。 2.7 倍数,网格渲染性能可以达到 4 倍以上。同时归功于 XMX 多个单元的引入 AI Xe2计算场景 同频性能可以达到上一代。 4 倍。

尤其值得注意的是,Xe2 对于结构的增强 Excute Indirect 硬件支持功能。而且这是最新版本 Direct 12 内部引入的技术特性,完全改变了 GPU 工作方法,让 GPU 无需再等候 CPU 指令,能主动“安排”高并发的指令 draw 和 dispatch 任务。
据实测数据显示,与过去依赖 CPU 进行“指挥” GPU Xe2与结构相比 这种改进促使其在新版本系统下得到改进。 dispatch 速度提升了 7 倍、draw 速度提升了 12.5 倍,无疑是革命性的增强。
当然,众所周知,要想充分发挥核显性能,就必须有足够的高带宽内存。以前, MeteorLake 上,英特尔虽然提供了对的服务 LPDDR5X-7500 支持内存,但不是强制性的 OEM 制造商使用这种高频内存。因此,它还为一些品牌“节约成本”,直接更换。 DDR5-5600 内存概率。

但到了 LunarLake 这一代,情况已经完全改变。由于新型Cpu直接采用集成内存设计,可以将其 16GB 或 32GB 的 LPDDR5X-8533 内存集成到 CPU 基板上。
虽然可以说这种设计也意味着 LunarLake 更多的内存是不可能适应的,但没关系,考虑到这一点, LunarLake 定位,其对应的同代“高性能向”移动平台,注定是今年同样登场的“箭湖”组合。后者采用了和 LunarLake 同宗同源的 CPU 为了满足移动工作站和下一代游戏本的需要,核心设计几乎可以支持更大容量的内存配置。
总结:主推低功耗,但也带来了新的希望。
总的来说,LunarLake 这是英特尔近年来变化最大的Cpu设计。如果根据代次之间的变化程度来判断,它的“创造力”甚至可能比较 11 代酷睿到 12 代酷睿的变化更大一些。
自然而然地不能否认,不管是最大的。 4P 4E 的 CPU 布局、最高 32GB 电影上的内存设计,还是它所用的集成? WiFi 这些都表明了新的计划 LunarLake 注定要更加注重“低功耗”、主要推广超轻薄笔记本电脑,x86 处理器设计,如掌机等。

官方已经明确表示,新架构也将用于桌面端新产品。
但是这样就会带来一个问题, LunarLake 现在已经不能完全覆盖了。 MeteorLake 因为后者毕竟有市场区间。 6P 8E 2LPE 在一些游戏本,甚至是工作站级别的产品中,使用了高功耗版本, LunarLake 也许不能满足他们的配置需求。
但是英特尔方面正在发展 LunarLake 在这个过程中也多次提到,这一次 CPU、GPU 采用可扩展的模块化结构。例如其 Skymont E 核心,将来在高性能处理器上肯定也会有。 8 核、16 核,甚至更多的核心数量版本,Lion Cove P 在更注重纯粹特性的“纯大核”Cpu上,核还可以完全添加超线程功能。

所以这显然意味着,LunarLake 这并不只是一代新的超轻薄。 AI 笔记本电脑芯片方案,其许多系统架构将在未来传承到英特尔新的高性能桌面。 CPU、高性能游戏本 CPU、独立显示,甚至在服务器和工作站产品线上。另一方面,这也代表着这一点。 LunarLake 英特尔全新软件优化、指令集提升生态、驱动适配服务的“新征程”很有可能成为可能。所以它的“战争未来”潜力,也许比我们现在想象的要大一些。
本文仅代表作者观点,版权归原创者所有,如需转载请在文中注明来源及作者名字。
免责声明:本文系转载编辑文章,仅作分享之用。如分享内容、图片侵犯到您的版权或非授权发布,请及时与我们联系进行审核处理或删除,您可以发送材料至邮箱:service@tojoy.com